GO基础
接口(interface)
接口是一种类型,是一种特殊的类型,它规定了变量有哪些方法
在编程中遇到一下场景:
我不关心一个变量是什么类型,我只关心调用什么方法
两个以上的结构体需要遵守一些共同的规则才需要定义接口
接口的定义
type 接口类型名 interface{
方法名1( 参数列表1 ) 返回值列表1
方法名2( 参数列表2 ) 返回值列表2
…
}
//例子:
type canCall interface {
speak()
}
接口的实现
一个变量实现了接口中规定的所有方法,那么这个变量就实现了这个接口。可以称之为接口的变量
使用值接受者实现接口与使用指针接受者实现接口垫区别?
- 使用值接受者实现接口:结构体类型和结构体指针的变量都能存
- 使用指针接受者实现接口:只能存结构指针类型的变量
接口和类型的关系
多个类型可以实现同一个接口
一个类型可以实现多个接口
空接口
空接口的定义
没有必要起名字,通常定义成下面的格式
interface() //空接口
所有的类型都实现了空接口,也就是任意类型的变量都能保存到空接口中。
使用途径
通常使用在map值类型和函数参数类型
//使用在map值类型上 var m1 map[string]interface{} //使用在函数上 func show(a interface{}){ fmt.Println(a) }
类型断言
想知道空接口接受的值具体是什么则使用类型断言
//方法1
func assign(i interface{}) {
fmt.Printf("%v", i)
str, ok := i.(string)
if !ok {
fmt.Println("不是string类型")
} else {
fmt.Printf("是string类型%s", str)
}
}
//方法2
func assign2(i interface{}) {
fmt.Printf("%v\n", i)
switch i.(type) {
case string:
fmt.Printf("这是一个字符串%s", i.(string))
case int:
fmt.Println("这是一个整数")
}
}
包(Package)
包的路径从``GOPATH/src
后面的路径开始写起,路径分隔符用/` (版本更新可能有变化)想被别的包调用的识别符都要首字母大写!
单行导入和多行导入
//单行导入 import work "01Package/work" //多行导入 import ( "fmt" funcs "01Package/func" )导入包的时候可以指定别名,如上
导入包不想使用包内部的标识符,需要使用匿名导入
import _ "01Package/work"每个包导入的时候自动执行一个名为intt()的函数,它没有参数也没有返回值也不能手动调用
多个包中都定义了init()函数,则它们的执行顺序见下图:
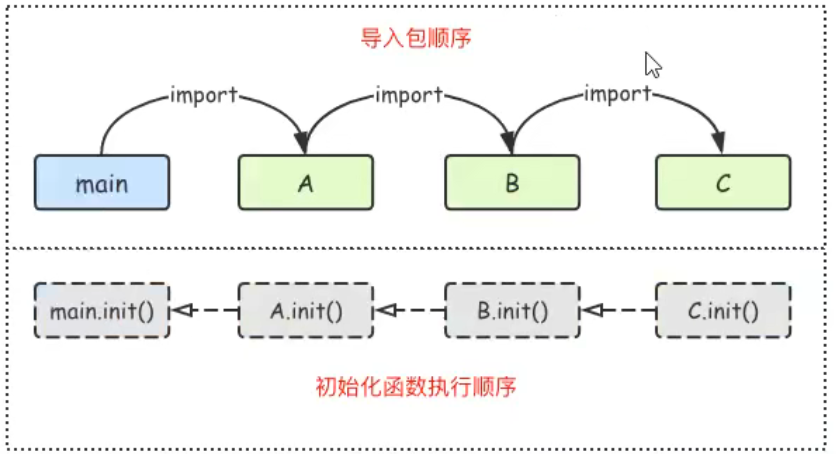
文件操作
打开文件
方法一(只能读)
fileObj, err := os.Open("./readfile.go") //打开资源
方法二(可读可写)
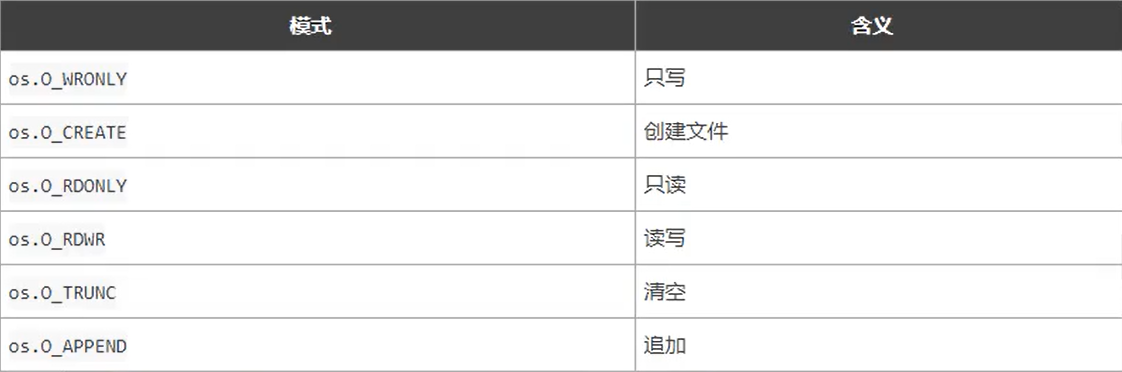
fileObj,err := os.OpenFile("xx.txt", os.O_WRONLY|os.O_APPEND|os.O_CREATE, 064)
读取操作
按字节读
fileObj, err := os.Open("./readfile.go")
n, err := fileObj.Read(b)
按行读
fileObj, err := os.Open("./readfile.go")
rdFile := bufio.NewReader(fileObj)
str, err := rdFile.ReadString('\n')
读取整片文章
str, err := ioutil.ReadFile("./readfile.go")
具体例子
package main
import (
"bufio"
"fmt"
"io/ioutil"
"os"
)
//按字节读
func fileReadDemo() {
fileObj, err := os.Open("./readfile.go") //打开资源
if err != nil {
fmt.Printf("读取是失败%v", err)
return
}
defer fileObj.Close() //关闭资源
b := make([]byte, 128)
for {
n, err := fileObj.Read(b)
if err != nil {
fmt.Println("读完了")
return
}
fmt.Printf("读取了%d\n", n)
fmt.Println(string(b))
}
}
//按行读
func fileReadBufio() {
fileObj, err := os.Open("./readfile.go")
if err != nil {
fmt.Printf("文件打开失败%v", err)
return
}
rdFile := bufio.NewReader(fileObj)
for {
str, err := rdFile.ReadString('\n')
if err != nil {
fmt.Println("读完了")
return
}
fmt.Print(str)
}
}
func filereadIoutil{
str, err := ioutil.ReadFile("./readfile.go")
if err != nil {
fmt.Printf("读取失败..%v", err)
return
}
fmt.Println(string(str))
}
func main() {
//fileReadDemo()
//fileReadbufio()
//filereadIoutil()
}
写入操作
按字节写
fileObj, err := os.OpenFile("./xx.txt", os.O_WRONLY|os.O_APPEND|os.O_CREATE, 0666)
fileObj.Write([]byte(str))
写在缓存再存
fileObj, err := os.OpenFile("./xx1.txt", os.O_WRONLY|os.O_APPEND|os.O_CREATE, 0664)
bw := bufio.NewWriter(fileObj)
bw.WriteString("张三李四王五")
bw.Flush()
直接写入
str := "wangwu"
ioutil.WriteFile("./xx1.txt", []byte(str), 0664)
具体例子
func file_write1() {
fileObj, err := os.OpenFile("./xx.txt", os.O_WRONLY|os.O_APPEND|os.O_CREATE, 0666)
if err != nil {
fmt.Printf("写入失败%v", err)
return
}
defer fileObj.Close()
str := "测试"
fileObj.Write([]byte(str))
}
func file_write2() {
fileObj, err := os.OpenFile("./xx1.txt", os.O_WRONLY|os.O_APPEND|os.O_CREATE, 0664)
if err != nil {
fmt.Println("写入失败")
}
defer fileObj.Close()
bw := bufio.NewWriter(fileObj)
bw.WriteString("张三李四王五")
bw.Flush()
}
func file_write3() {
str := "wangwu"
ioutil.WriteFile("./xx1.txt", []byte(str), 0664)
}
运行时
获取运行时的文件信息
runtime.Caller()
time标准库
时间对象
time.Now()
时间信息
// timeDemo 时间对象的年月日时分秒
func timeDemo() {
now := time.Now() // 获取当前时间
fmt.Printf("current time:%v\n", now)
year := now.Year() // 年
month := now.Month() // 月
day := now.Day() // 日
hour := now.Hour() // 小时
minute := now.Minute() // 分钟
second := now.Second() // 秒
fmt.Println(year, month, day, hour, minute, second)
}
时间操作
时间相加
#时间加小时\分钟
now := time.Now()
now.Add(24*time.Hour)
两个时间相减
#两个时间相减
now := time.Now()
newNow:= time.Now()
now.Sub(newNow)
时间戳
now := time.Now()
now.Unix()
now.UnixNano()
时间戳转换成时间格式
time.Unix(1564803667, 0)
定时器
ticker := time.Tick(time.Second) //time.Second时间间隔
for i := range ticker {
fmt.Println(i)
}
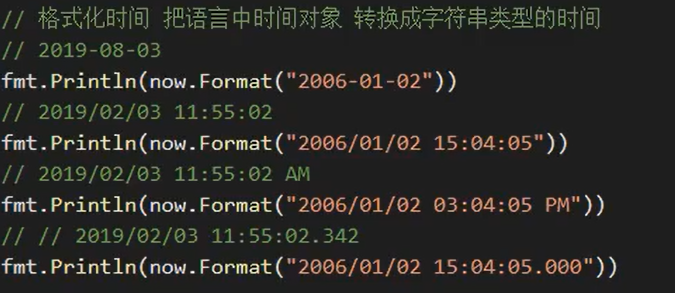
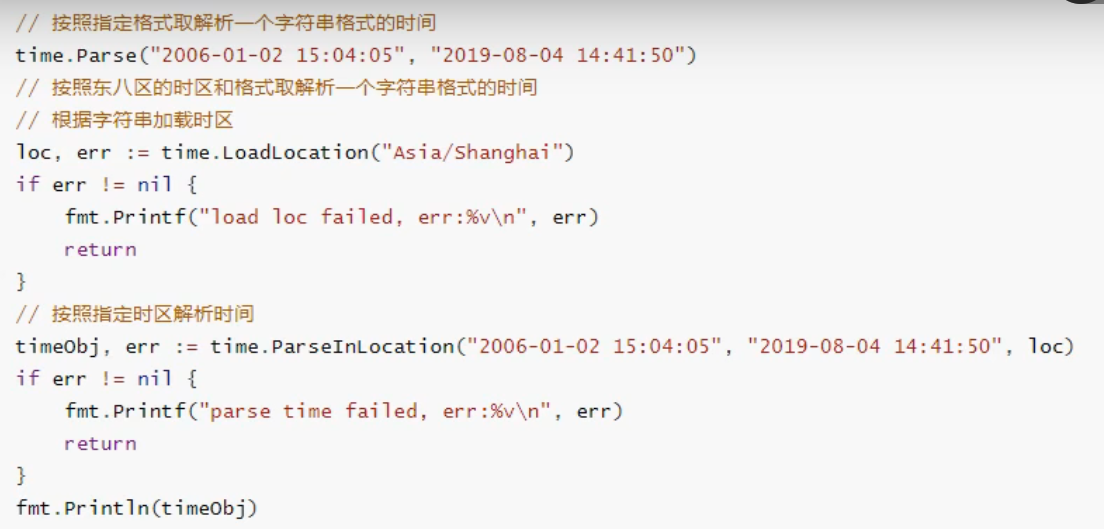
时间格式化
格式模板:2006-1-2 15:04:05
日志库操作实例

代码见
反射
接口类型的变量底层是分为两部分:动态类型和动态值
反射的应用:
json等数据解析\ORM等工具.....
反射的两个方法
方法一
reflect.TypeOf()
//获取字段信息
方法二
reflect.ValueOf()
//赋值等操作
strconv标准库
字符串转整数
转其他类型也类似
strconv.ParseInt("1000",10,64)
并发
goroutine
启动goroutine
func hello(i int) {
fmt.Printf("hello%d\n", i)
}
func main() {
for i := 1; i < 100; i++ {
//go hello(i) //启动一个goroutine
go func(i int) {
fmt.Printf("hello1:%d\n", i)
}(i)
}
fmt.Println("main")
}
goroutine什么结束
goroutine对应的函数结束了,goroutine结束了
goroutine调动模型
GMP
G 表示goroutine
M表示和操作系统一个映射的关系
P调度着管理goroutine执行什么任务,goroutine的上下文,goroutine遇到IO阻塞该怎么办
M:N
M:N 把m个goroutine分配给n个操作系统线程去执行
goroutine初始栈的大小是2K
channel
通道
声明通道
var b chan int //需要指定通道中元素的类型
通道必须使用make函数初始化才能使用
b = make(chan int) //不带缓冲区通道的初始化 b = make(chan int,16) //带缓冲区的通道初始化
通道的操作
ch1 为定义的通道变量名
发送
ch1 <- 1
接受
x := <- ch1
关闭
close()
select
- 可处理一个或多个 channel 的发送/接收操作。
- 如果多个 case 同时满足,select 会随机选择一个执行。
- 对于没有 case 的 select 会一直阻塞,可用于阻塞 main 函数,防止退出。
select使用
select {
case f.logtmp <- logtmp:
//fmt.Println("开始写入")
default:
//os.Exit(0)
}
sync
sync包Mutex(互斥锁)
sync.Mutex 是一个结构体,是值类型,给函数传参数的时候要传指针
互斥锁是一种常用的控制共享资源访问的方法,它能够保证同一时间只有一个 goroutine 可以访问共享资源
开锁
var lock sync.Mutex
lock.Lock() //加锁
关锁
var lock sync.Mutex
lock.Unlock() //解锁
使用案例
var x int
func add() {
for i := 0; i < 10000; i++ {
lock.Lock() //加锁
x = x + 1
lock.Unlock() //解锁
}
wg.Done()
}
var wg sync.WaitGroup
var lock sync.Mutex
func main() {
wg.Add(2)
go add()
go add()
wg.Wait()
fmt.Println(x)
}
sync包RWMutex(读写互斥锁)
读写锁分为两种:
读锁和写锁
- 当一个 goroutine 获取到读锁之后,其他的 goroutine 如果是获取读锁会继续获得锁,如果是获取写锁就会等待;
- 而当一个 goroutine 获取写锁之后,其他的 goroutine 无论是获取读锁还是写锁都会等待。
读锁
var rwlock sync.RWMutex
rwlock.RLock()//加锁
rwlock.RUnlock()//解锁
写锁
var rwlock sync.RWMutex
rwlock.Lock()//加锁
rwlock.Unlock()//解锁
sync包waitGroup(等待组)
sync.waitGroup是一个结构体,是值类型,给函数传参数的时候要传指针
使用此来使goroutine同步,所有goroutine执行完才结束程序
使用方法案例
func hello(i int) {
fmt.Printf("hello%d\n", i)
wg.Done() //计数器减一
}
var wg sync.WaitGroup
func tsleep(i int) {
rand.Seed(time.Now().UnixNano())
time.Sleep(time.Second * time.Duration(rand.Intn(3)))
go hello(i)
wg.Add(1) //计数器加一
}
func main() {
for i := 1; i < 10; i++ {
tsleep(i)
}
wg.Wait() //等待goroutine执行完毕
}
sync包Once
在某些场景下我们需要确保某些操作即使在高并发的场景下也只会被执行一次,例如只加载一次配置文件等。
操作案例
var icons map[string]image.Image
var loadIconsOnce sync.Once
func loadIcons() {
icons = map[string]image.Image{
"left": loadIcon("left.png"),
"up": loadIcon("up.png"),
"right": loadIcon("right.png"),
"down": loadIcon("down.png"),
}
}
// Icon 是并发安全的
func Icon(name string) image.Image {
loadIconsOnce.Do(loadIcons) //所有goroutine只执行一次loadIcons操作
return icons[name]
}
sync包Map
操作案例
var m = sync.Map{}
func main() {
wg := sync.WaitGroup{}
for i := 0; i < 20; i++ {
wg.Add(1)
go func(n int) {
key := strconv.Itoa(n)
m.Store(key, n) //添加元素
value, _ := m.Load(key) //查看值
fmt.Printf("key:%s value:%d\n", key, value)
wg.Done()
}(i)
}
wg.Wait()
}
原子操作atomic
针对整数数据类型(int32、uint32、int64、uint64)我们还可以使用原子操作来保证并发安全,通常直接使用原子操作比使用锁操作效率更高
操作实例
var (
x int64
wg sync.WaitGroup
)
func add() {
atomic.AddInt64(&x, 1)
wg.Done()
}
func main() {
for i := 0; i < 10000; i++ {
wg.Add(1)
go add()
}
wg.Wait()
fmt.Println(x)
}
随机数(math/rand)
rand.Seed(time.Now().UnixNano()) //确保每次随机数不一样
for i := 1; i < 10; i++ {
r1 := rand.Intn(10)
fmt.Println(r1)
}
互联网协议介绍
OSI七层模型
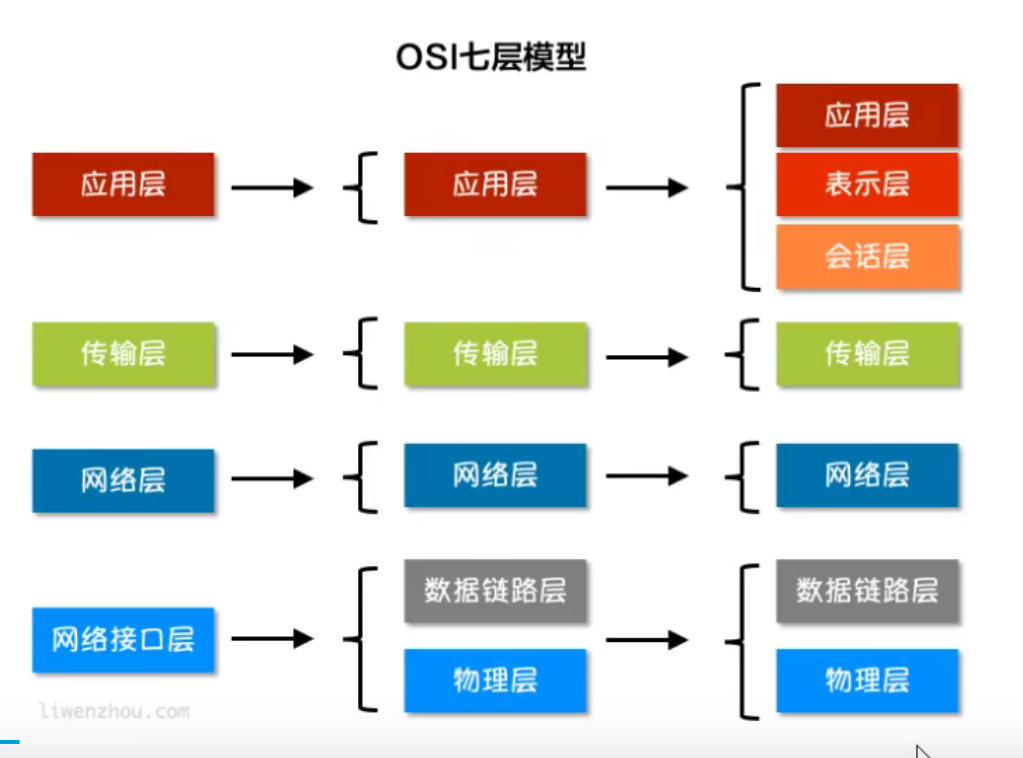
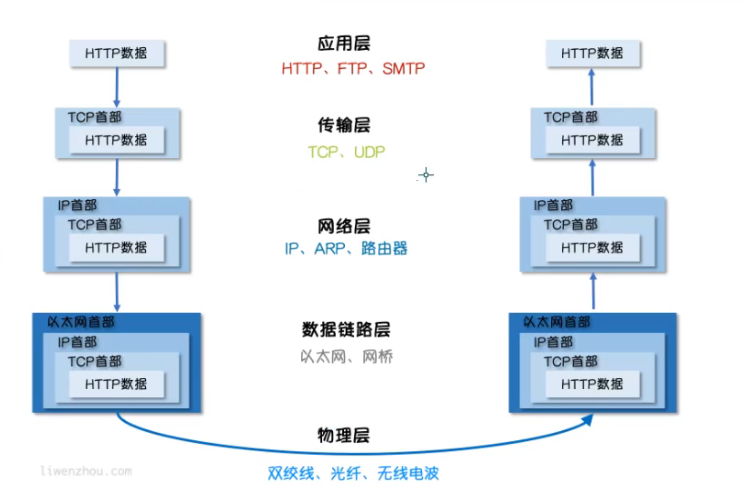
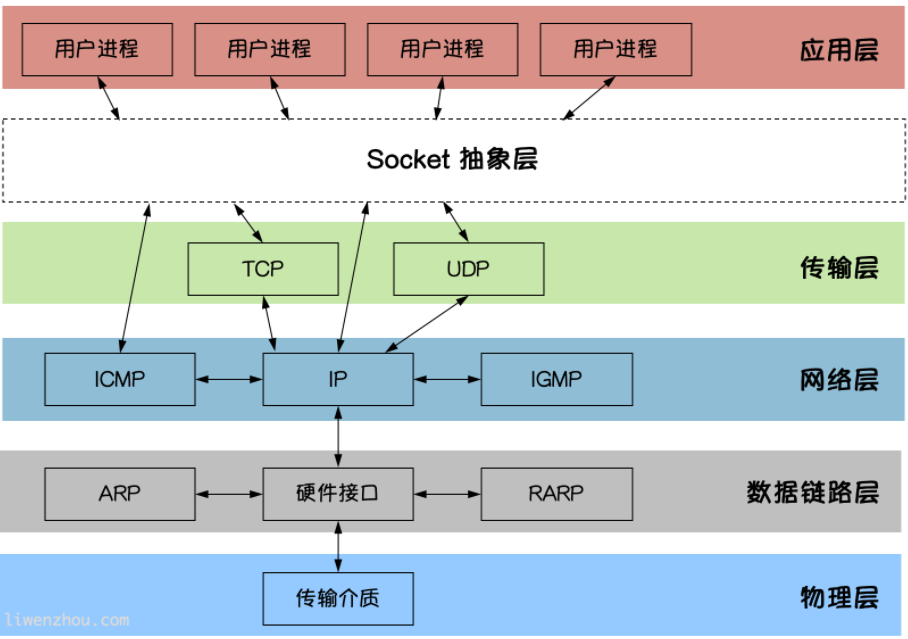
socket编程
Socket是应用层与TCP/IP协议族通信的中间软件抽象层。在设计模式中,Socket其实就是一个门面模式,它把复杂的TCP/IP协议族隐藏在Socket后面,对用户来说只需要调用Socket规定的相关函数,让Socket去组织符合指定的协议数据然后进行通信。
实现TCP通讯
TCP/IP(Transmission Control Protocol/Internet Protocol) 即传输控制协议/网间协议,是一种面向连接(连接导向)的、可靠的、基于字节流的传输层(Transport layer)通信协议,因为是面向连接的协议,数据像水流一样传输,会存在黏包问题。
TCP服务端
//TCP server 服务端
/*
1.创建连接
2.等待连接
3.接受通讯
*/
func processConn(conn net.Conn) {
var news [128]byte
for {
n, err := conn.Read(news[:])
if err != nil {
fmt.Printf("read news failed err:%v", err)
}
fmt.Println(string(news[:n]))
}
conn.Close()
}
func main() {
//1.创建连接
listener, err := net.Listen("tcp", "127.0.0.1:2000")
if err != nil {
fmt.Printf("start 127.0.0.1:9000 server failed, err%v", err)
}
defer listener.Close() //函数关闭 关闭连接
//2.等待连接
for {
conn, err := listener.Accept()
if err != nil {
fmt.Printf("accept failed err :%v", err)
}
//3.接受通讯
go processConn(conn)
}
}
TCP客户端
//TCP client客户端
/*
1.连接服务端
2.发送信息
*/
func main() {
//1.连接服务端
conn, err := net.Dial("tcp", "127.0.0.1:2000")
if err != nil {
fmt.Printf("dial 127.0.0.1:9000 failed err:%v", err)
return
}
//2.发送信息
for {
reader := bufio.NewReader(os.Stdin) //创建一个缓存区储存控制台信息
str, err := reader.ReadString('\n') //按行读
if err != nil {
fmt.Printf("read stdin failed err %v", err)
}
_, err = conn.Write([]byte(str)) //发送信息
if err != nil {
fmt.Printf("write news failed err:%v", err)
}
}
conn.Close()
//var b []byte
}
TCP黏包
解决方法
// socket_stick/proto/proto.go
package proto
import (
"bufio"
"bytes"
"encoding/binary"
)
// Encode 将消息编码
func Encode(message string) ([]byte, error) {
// 读取消息的长度,转换成int32类型(占4个字节)
var length = int32(len(message))
var pkg = new(bytes.Buffer)
// 写入消息头
err := binary.Write(pkg, binary.LittleEndian, length)
if err != nil {
return nil, err
}
// 写入消息实体
err = binary.Write(pkg, binary.LittleEndian, []byte(message))
if err != nil {
return nil, err
}
return pkg.Bytes(), nil
}
// Decode 解码消息
func Decode(reader *bufio.Reader) (string, error) {
// 读取消息的长度
lengthByte, _ := reader.Peek(4) // 读取前4个字节的数据
lengthBuff := bytes.NewBuffer(lengthByte)
var length int32
err := binary.Read(lengthBuff, binary.LittleEndian, &length)
if err != nil {
return "", err
}
// Buffered返回缓冲中现有的可读取的字节数。
if int32(reader.Buffered()) < length+4 {
return "", err
}
// 读取真正的消息数据
pack := make([]byte, int(4+length))
_, err = reader.Read(pack)
if err != nil {
return "", err
}
return string(pack[4:]), nil
}
大端小端
存储方式
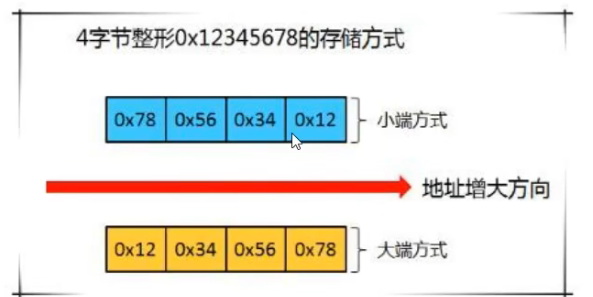
实现UDP通讯
UDP协议(User Datagram Protocol)中文名称是用户数据报协议,是OSI(Open System Interconnection,开放式系统互联)参考模型中一种无连接的传输层协议,不需要建立连接就能直接进行数据发送和接收,属于不可靠的、没有时序的通信,但是UDP协议的实时性比较好,通常用于视频直播相关领域
UDP服务端
package main
import (
"fmt"
"net"
"strings"
)
//UDP 客户端
func main() {
//1.创建连接
listenudp, err := net.ListenUDP("udp", &net.UDPAddr{
IP: net.IPv4(127, 0, 0, 1),
Port: 8008,
})
if err != nil {
fmt.Printf("start listen UDP falied errer err:%v", err)
}
defer listenudp.Close()
var accept [128]byte
for {
n, addr, err := listenudp.ReadFromUDP(accept[:]) // 接受数据
if err != nil {
fmt.Println("read udp failed err:", err)
}
fmt.Println(string(accept[:n]))
_, err = listenudp.WriteToUDP([]byte(strings.ToUpper(string(accept[:n]))), addr) //发送数据
if err != nil {
fmt.Println("write to udp failed err:", err)
}
}
}
UDP客户端
package main
import (
"bufio"
"fmt"
"net"
"os"
)
func main() {
socket, err := net.DialUDP("udp", nil, &net.UDPAddr{
IP: net.IPv4(127, 0, 0, 1),
Port: 8008,
})
if err != nil {
fmt.Println("dial udp failed err:", err)
}
defer socket.Close()
reader := bufio.NewReader(os.Stdin)
for {
str, _ := reader.ReadString('\n')
socket.Write([]byte(str)) //发送数据
var b [1024]byte
n, _, err := socket.ReadFromUDP(b[:])
if err != nil {
fmt.Println("read from udp failed err", err)
}
fmt.Println(string(b[:n]))
}
}
HTTP
server端
package main
import (
"fmt"
"io/ioutil"
"net/http"
)
//http server 服务端
func hello(w http.ResponseWriter, r *http.Request) {
b, err := ioutil.ReadFile("./hello.html")
if err != nil {
w.Write([]byte("404"))
}
w.Write(b)
}
func getdata(w http.ResponseWriter, r *http.Request) {
fmt.Println(r.Method)
fmt.Println(r.URL.Query().Get("name"))
w.Write([]byte("ok"))
}
func main() {
http.HandleFunc("/hello", hello)
http.HandleFunc("/getdata/", getdata)
http.ListenAndServe("127.0.0.1:800", nil)
}
client端
package main
import (
"fmt"
"io/ioutil"
"net/http"
)
func main() {
rep, err := http.Get("http://127.0.0.1:800/getdata/?name=123")
if err != nil {
fmt.Println("get failed err:", err)
}
defer rep.Body.Close()
str, err := ioutil.ReadAll(rep.Body)
if err != nil {
fmt.Println(err)
}
fmt.Println(string(str))
}
context
单元测试
开发自己给自己的代码写测试
Go语言中的测试依赖
go test命令。编写测试代码和编写普通的Go代码过程是类似的,并不需要学习新的语法、规则或工具。
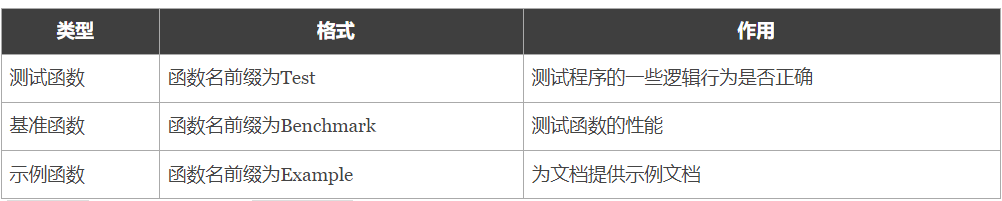
测试函数
测试函数模板
功能函数
此功能函数用于下列的所有的测试函数
package split_string
import "strings"
func Split(str, stB string) []string {
index := strings.Index(str, stB)
var ret []string
for index > -1 {
ret = append(ret, str[:index])
str = str[index+len(stB):]
index = strings.Index(str, stB)
}
ret = append(ret, str)
return ret
}
函数必须以
TestXXX为名称,参数必须是t testing .T命令行输入
go test进行测试
package split_string
import (
"reflect"
"testing"
)
func TestSplit(t *testing.T) {
pot := Split("a:b:c", ":")
want := []string{"a", "b", "c"}
if !reflect.DeepEqual(pot, want) {
t.Errorf("got:%v want:%v", pot, want)
}
}
测试组模板
func TestSplit(t *testing.T) {
type testStruct struct {
str string //总的字符串
stB string //切割字符串
want []string //希望切割后的结果
}
testGroup := []testStruct{
{str: "a:b:c", stB: ":", want: []string{"a", "b", "c"}},
{str: "123123424", stB: "2", want: []string{"1", "31", "34", "4"}},
{str: "testtset", stB: "t", want: []string{"", "es", "", "se", ""}},
}
for _, value := range testGroup {
pot := Split(value.str, value.stB)
if !reflect.DeepEqual(pot, value.want) {
t.Errorf("got:%#v want:%#v", pot, value.want)
}
}
}
子测试模板
go test -v -run=TestSplit/string单独测试某一个
TestSplit为函数名string为map中的key
package split_string_zon
import (
"reflect"
"testing"
)
func TestSplit(t *testing.T) {
type testStruct struct {
str string //总的字符串
stB string //切割字符串
want []string //希望切割后的结果
}
testGroup := map[string]testStruct{
"abc": {str: "a:b:c", stB: ":", want: []string{"a", "b", "c"}},
"num": {str: "123123424", stB: "2", want: []string{"1", "31", "34", "4"}},
"string": {str: "testtset", stB: "t", want: []string{"", "es", "", "se", ""}},
}
for name, value := range testGroup {
t.Run(name, func(t *testing.T) {
pot := Split(value.str, value.stB)
if !reflect.DeepEqual(pot, value.want) {
t.Errorf("got:%#v want:%#v", pot, value.want)
}
})
}
}
测试覆盖率
go test -cover测试覆盖率
go test -cover -coverprofile=c.out覆盖率相关的记录信息输出到c.out文件中
go tool cover -html=c.out使用浏览器窗口生成一个html报告
基准测试
基准测试函数格式
func BenchmarkSplit(b *testing.B){
//b.N 被测试函数执行的次数
}
执行命令
go test -bench -v
性能比较测试
pprof调试工具
记录CPU快照信息
记录内存的快照信息
flag包(控制台参数)
Go语言内置的
flag包实现了命令行参数的解析,flag包使得开发命令行工具更为简单。
os.Args
获取命令行参数
package main
import (
"fmt"
"os"
)
func main() {
//获取命令行参数
fmt.Printf("type:%T,%v\n", os.Args, os.Args)
//type:[]string,[01.exe]
fmt.Println(os.Args[1])
//type:[]string,[01.exe 1 2 3]
//1
}
添加标志
package main
import (
"flag"
"fmt"
)
func main() {
//添加标志
//第一种方式
name := flag.String("name", "张三", "你的名字是什么?")
//第二种方式
var age int
flag.IntVar(&age, "age", 18, "你多少岁?")
flag.Parse() //解析flag
fmt.Println(*name)
fmt.Println(age)
/*
//命令行输入的
D:\GoPackage\src\com.haojuetracePackage\flag_Demo>02.exe -name zhansna -age 11
zhansna
11
*/
}
其他方法
flag.Args() ////返回命令行参数后的其他参数,以[]string类型
flag.NArg() //返回命令行参数后的其他参数个数
flag.NFlag() //返回使用的命令行参数个数
解析flag
flag.Parse() //解析flag
面试题分享
算法题库
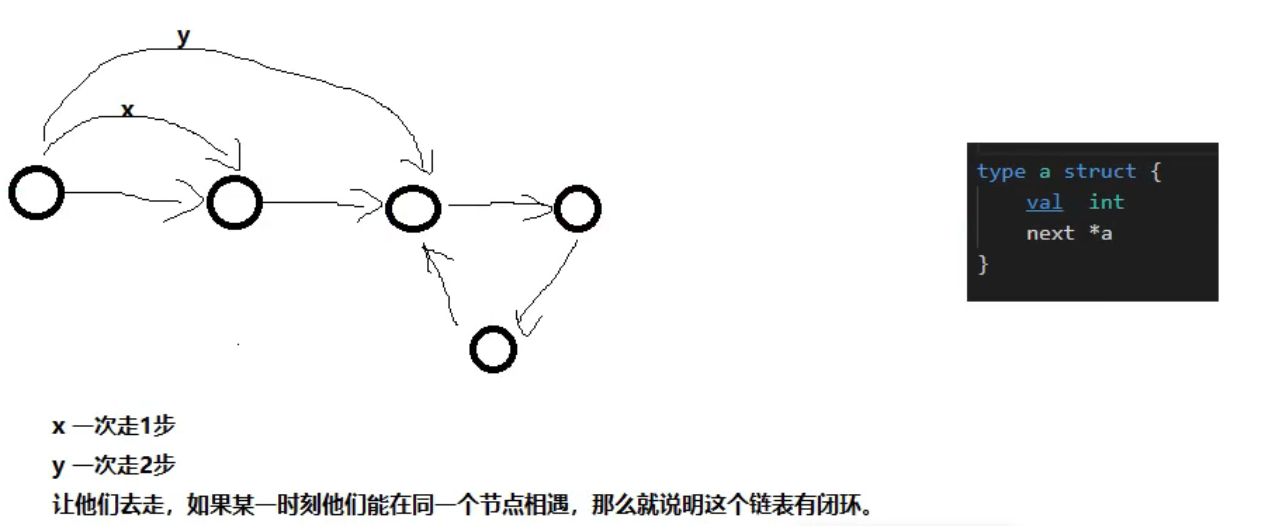
如何判断一个链表有没有闭环?
MySQL
数据库
常见的数据库SQLlite、MySQL、SQLServer、postgreSQL、Oracle
主流的关系型数据库,类似的还有postgreSQL
go操作MySql
database/sql
原生支持连接池,是并发安全的
这个标准库没有具体的实现,只是列出了一些需要第三方库实现的具体内容
下载驱动
go get包的路径就是下载第三方的依赖将第三方的依赖默认保存在
$GOPATH/src/
go get -u github.com/go-sql-driver/mysql
使用驱动
dsn := "root:123456@(127.0.0.1:3306)/college"
db, err := sql.Open("mysql", dsn)
具体实例
package main
import (
"database/sql"
"fmt"
_ "github.com/go-sql-driver/mysql"
)
func main() {
dsn := "root:123456@(127.0.0.1:3306)/college"
db, err := sql.Open("mysql", dsn) //打开驱动连接
if err != nil {
fmt.Printf("%s failed err:%v\n", dsn, err)
return
}
err = db.Ping() //测试是否连接成功
if err != nil {
fmt.Printf("open %s failed err%v\n", dsn, err)
return
}
fmt.Println("连接数据库成功")
}
数据库操作(增删改查)
查询单条
dsn := "root:123456@(127.0.0.1)/stuinfo"
db, err = sql.Open("mysql", dsn)
sqlStr := `select id,sNo,sName,sex,birthday,deptName from student where sNo=?`
//查询并获取结果
err := db.QueryRow(sqlStr, sNos).Scan(&s.id, &s.sNo, &s.sName, &s.sex, &s.birthday, &s.deptName)
具体实例
package main
import (
"database/sql"
"fmt"
"time"
_ "github.com/go-sql-driver/mysql"
)
var db *sql.DB
type student struct {
id int
sNo string
sName string
sex string
birthday string
deptName string
}
func queryOne(sNos string) (s student) {
sqlStr := `select id,sNo,sName,sex,birthday,deptName from student where sNo=?`
//查询并获取结果 非常重要:确保QueryRow之后调用Scan方法,否则持有的数据库链接不会被释放
err := db.QueryRow(sqlStr, sNos).Scan(&s.id, &s.sNo, &s.sName, &s.sex, &s.birthday, &s.deptName)
if err != nil {
fmt.Println("select faided Err:", err)
}
return s
}
func intnDB() (err error) {
dsn := "root:123456@(127.0.0.1)/stuinfo"
db, err = sql.Open("mysql", dsn)
if err != nil {
return
}
err = db.Ping()
if err != nil {
return
}
db.SetMaxOpenConns(10) //设置最多连接数
db.SetConnMaxLifetime(time.Second * 30) //设置可以重用连接的最长时间
db.SetMaxIdleConns(5) //设置最多空闲数
return nil
}
func main() {
err := intnDB()
if err != nil {
fmt.Printf("open mysql failed err%v\n", err)
}
fmt.Println("数据连接成功")
s := queryOne("1308013101")
fmt.Printf("%#v\n", s)
}
查询多条
dsn := "root:123456@(127.0.0.1)/stuinfo"
db, err = sql.Open("mysql", dsn)
sqlStr := `select id,sNo,sName,sex,birthday,deptName from student where deptName=?`
rows, err := db.Query(sqlStr, "软件101")
defer rows.Close()
具体实例
func queryMany(deptName string) (ss []student, err error) {
ss = make([]student, 0)
sqlStr := `select id,sNo,sName,sex,birthday,deptName from student where deptName=?`
rows, err := db.Query(sqlStr, deptName)
if err != nil {
err = errors.New(fmt.Sprintf("%s syntax failed err: %v", sqlStr, err))
return nil, err
}
defer rows.Close()
var s student
for rows.Next() {
rows.Scan(&s.id, &s.sNo, &s.sName, &s.sex, &s.birthday, &s.deptName)
ss = append(ss, s)
}
return ss, nil
}
mysql取datetime类型数据问题解决
//问题报错
sql: Scan error on column index 1: unsupported driver -> Scan pair: []uint8 -> *time.Time
//解决方案
//先将datetime的字面值赋值给string变量。然后通过time.Parse(layout, value)转换为time.Time类型
例:
var cCreateat, cUpdataAt string
_ = c.Db.QueryRow(sqlStr, value).Scan(&classify.Id, &classify.Name, &cCreateat, &cUpdataAt)
classify.CreateAt, _ = time.Parse("2006-01-02 15:04:05", cCreateat)
插入数据
dsn := "root:123456@(127.0.0.1)/stuinfo"
db, err = sql.Open("mysql", dsn)
sqlStr := `insert student (sNo,sName,sex,birthday,deptName) values("1312054906","张三","男","2016-5-12","云计算1")`
ret, err := db.Exec(sqlStr)
具体实例
//插入数据
func insertRowDemo() {
sqlStr := `insert student (sNo,sName,sex,birthday,deptName) values("1312054906","张三","男","2016-5-12","云计算1")`
ret, err := db.Exec(sqlStr)
if err != nil {
fmt.Printf("%s syntax failed err: %v", sqlStr, err)
return
}
id, err := ret.LastInsertId()
if err != nil {
fmt.Println("get id failed err :", err)
return
}
fmt.Println("id:", id)
}
修改数据
dsn := "root:123456@(127.0.0.1)/stuinfo"
db, err = sql.Open("mysql", dsn)
sqlStr := `UPDATE student SET sName="李四2" WHERE id=22`
ret, err := db.Exec(sqlStr)
具体实例
func updataRowDemo() {
sqlStr := `UPDATE student SET sName="李四2" WHERE id=22`
ret, err := db.Exec(sqlStr)
if err != nil {
fmt.Printf("%s syntax failed err: %v", sqlStr, err)
return
}
n, err := ret.RowsAffected()
if err != nil {
fmt.Println("get row affected failed err :", err)
return
}
fmt.Printf("修改了:%d行", n)
}
删除数据
dsn := "root:123456@(127.0.0.1)/stuinfo"
db, err = sql.Open("mysql", dsn)
sqlStr := `delete from student where id=22`
ret, err := db.Exec(sqlStr)
具体实例
//删除数据
func deleteRowDemo() {
sqlStr := `delete from student where id=22`
ret, err := db.Exec(sqlStr)
if err != nil {
fmt.Printf("%s syntax failed err: %v", sqlStr, err)
return
}
n, err := ret.RowsAffected()
if err != nil {
fmt.Println("get row affected failed err :", err)
return
}
fmt.Printf("删除了:%d行", n)
}
mysql预处理
预处理执行过程:
- 把SQL语句分成两部分,命令部分与数据部分。
- 先把命令部分发送给MySQL服务端,MySQL服务端进行SQL预处理。
- 然后把数据部分发送给MySQL服务端,MySQL服务端对SQL语句进行占位符替换。
- MySQL服务端执行完整的SQL语句并将结果返回给客户端。
为什么要预处理?
- 优化MySQL服务器重复执行SQL的方法,可以提升服务器性能,提前让服务器编译,一次编译多次执行,节省后续编译的成本。
- 避免SQL注入问题。
func (db *DB)Prepare(query string)(*Stmt,error)
具体实例
//通过预处理插入多条数据
func prepareInsert() {
sqlStr := `insert student (sNo,sName,sex,birthday,deptName) values(?,?,?,?,?)`
stmt, err := db.Prepare(sqlStr) //预处理sql语句
if err != nil {
fmt.Printf("prepare failed err%v\n", err)
return
}
var s = []student{{
sNo: "1309121111",
sName: "张三1",
sex: "男",
birthday: "2002-05-12",
deptName: "云计算2班",
}, {
sNo: "1309122222",
sName: "张三2",
sex: "男",
birthday: "2002-05-13",
deptName: "云计算2班",
}, {
sNo: "1309123333",
sName: "张三3",
sex: "男",
birthday: "2002-05-15",
deptName: "云计算2班",
}}
for _, v := range s {
stmt.Exec(v.sNo, v.sName, v.sex, v.birthday, v.deptName) //插入数据
}
fmt.Printf("成功插入%d条数据", len(s))
}
事务
开启事务
func (db *DB) Begin() (*Tx, error)
提交事务
func (tx *Tx) Commit() error
回滚事务
func (tx *Tx) Rollback() error
具体实例
func affairDemo() {
sqlStr1 := `update score set grade=grade-2 where id=1`
// sqlStr2 := `update score set grade=grade+2 where id=3` //正常运行的
sqlStr2 := `update score set grade=grade+2 xxxx id=3` //模拟出错
tx, err := db.Begin() //开启事务
if err != nil {
fmt.Println("开启事务失败 err:", err)
}
_, err = tx.Exec(sqlStr1)
if err != nil {
tx.Rollback() //回滚事务
fmt.Println("sql1执行失败,进入回滚")
return
}
_, err = tx.Exec(sqlStr2)
if err != nil {
tx.Rollback() //回滚事务
fmt.Println("sql2执行失败,进入回滚")
return
}
tx.Commit() //提交事务
fmt.Println("事务执行成功")
}
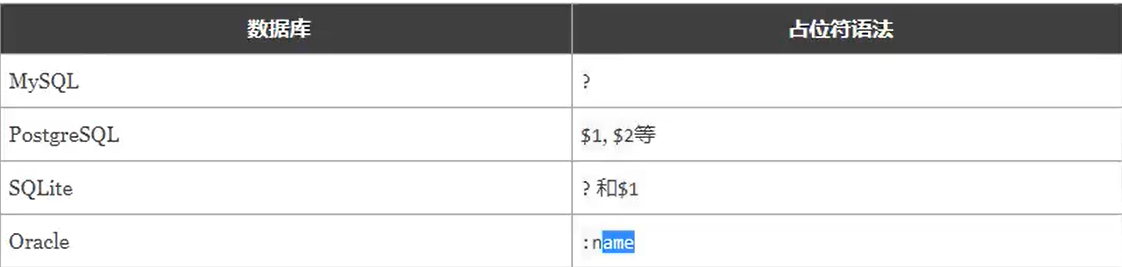
占位符区别
sqlx
第三方库
sqlx能够简化操作,提高开发效率
Redis
KV数据库
Redis的用处:
- cache缓存
- 简单的队列
- 排名榜
Redis支持的数据结构
Redis支持诸如字符串(string)、哈希(hashe)、列表(list)、集合(set)、带范围查询的排序集合(sorted set)、bitmap、hyperloglog、带半径查询的地理空间索引(geospatial index)和流(stream)等数据结构。
package main
import (
"fmt"
"github.com/go-redis/redis"
)
var redisDb *redis.Client
func main() {
redisDb = redis.NewClient(&redis.Options{
Addr: "127.0.0.1:6379",
Password: "",
DB: 0,
})
redisDb.Ping()
fmt.Println("连接成功")
}
其他内容要补
NSQ
生产者
package main
import (
"fmt"
"github.com/nsqio/go-nsq"
)
func main() {
addr := "127.0.0.1:4150"
config := nsq.NewConfig()
producer, err := nsq.NewProducer(addr, config)
if err != nil {
fmt.Println("连接失败", err)
return
}
err = producer.Publish("test_demo", []byte("ceshi demo"))
if err != nil {
fmt.Println("发送消息失败 err :", err)
}
}
消费者
// nsq_consumer/main.go
package main
import (
"fmt"
"os"
"os/signal"
"syscall"
"time"
"github.com/nsqio/go-nsq"
)
// NSQ Consumer Demo
// MyHandler 是一个消费者类型
type MyHandler struct {
Title string
}
// HandleMessage 是需要实现的处理消息的方法
func (m *MyHandler) HandleMessage(msg *nsq.Message) (err error) {
fmt.Printf("%s recv from %v, msg:%v\n", m.Title, msg.NSQDAddress, string(msg.Body))
return
}
// 初始化消费者
func initConsumer(topic string, channel string, address string) (err error) {
config := nsq.NewConfig()
config.LookupdPollInterval = 15 * time.Second
c, err := nsq.NewConsumer(topic, channel, config)
if err != nil {
fmt.Printf("create consumer failed, err:%v\n", err)
return
}
consumer := &MyHandler{
Title: "dsg111",
}
c.AddHandler(consumer)
// if err := c.ConnectToNSQD(address); err != nil { // 直接连NSQD
if err := c.ConnectToNSQLookupd(address); err != nil { // 通过lookupd查询
return err
}
return nil
}
func main() {
err := initConsumer("test_demo", "first", "127.0.0.1:4161")
if err != nil {
fmt.Printf("init consumer failed, err:%v\n", err)
return
}
c := make(chan os.Signal) // 定义一个信号的通道
signal.Notify(c, syscall.SIGINT) // 转发键盘中断信号到c
<-c // 阻塞
}
包的依赖管理go module
Go1.11之后官方出的依赖管理工具
goproxy
设置代理,下载墙外的库更快
export GOPROXY=https://goproxy.cn #mac或者linux
set GOPROXY=https://goproxy.cn #windows
go mod命令
#常用命令
go mod init [包名] #初始化当前文件夹, 创建go.mod文件
go mod tidy #增加缺少的module,删除无用的module
go mod download #下载依赖的module到本地cache(默认为$GOPATH/pkg/mod目录)
go get #获取依赖
#其他命令
go mod edit #编辑go.mod文件
go mod graph #打印模块依赖图
go mod vendor #将依赖复制到vendor下
go mod verify #校验依赖
go mod why #解释为什么需要依赖
go mod文件
记录当前以来的第三方包信息和版本信息
第三方的依赖包都下载到了``GOPATH/pkg/mod`目录下
go sum文件
详细包名和版本信息
Context
非常重要!
如何优雅的控制zigoroutine退出?
两个默认值
context.Background()
context.TODO()
简单案例
func f2(ctx context.Context) {
defer wg.Done()
for {
fmt.Println("f1")
time.Sleep(time.Millisecond * 500)
select {
case <-ctx.Done():
break
default:
}
}
}
func main() {
ctx, cancel := context.WithCancel(context.Background())
wg.Add(1)
go f1(ctx)
time.Sleep(time.Second * 5)
cancel() //调用cancel关闭子goroutine
}
withDeadline
返回父上下文的副本,并将deadline调整为不迟于d。如果父上下文的deadline已经早于d,则WithDeadline(parent, d)在语义上等同于父上下文。当截止日过期时,当调用返回的cancel函数时,或者当父上下文的Done通道关闭时,返回上下文的Done通道将被关闭,以最先发生的情况为准。
func main() {
// news := time.Now().Add(50 * time.Millisecond)
news := time.Now().Add(2000 * time.Millisecond)
ctx, cancel := context.WithDeadline(context.Background(), news)
// 尽管ctx会过期,但在任何情况下调用它的cancel函数都是很好的实践。
// 如果不这样做,可能会使上下文及其父类存活的时间超过必要的时间。
defer cancel()
select {
case <-time.After(1 * time.Second):
fmt.Println("zhangsan")
case <-ctx.Done():
fmt.Println(ctx.Err())
}
}
withTimeout
类似于withDeadline
var wg sync.WaitGroup
var judge bool = false
func dbDemo(ctx context.Context) {
println("模拟mysql连接")
time.Sleep(100 * time.Millisecond)
judge = true
}
func worker(ctx context.Context) {
go dbDemo(ctx)
loop:
for {
select {
case <-ctx.Done():
if judge {
println("mysql连接成功")
} else {
println("mysql连接失败")
}
break loop
default:
}
}
wg.Done()
}
func main() {
ctx, cancal := context.WithTimeout(context.Background(), 50*time.Millisecond)
wg.Add(1)
go worker(ctx)
time.Sleep(5 * time.Second)
cancal()
wg.Wait()
}
withValue
package main
import (
"context"
"fmt"
"sync"
"time"
)
type TraceCode string
var wg sync.WaitGroup
func worker(ctx context.Context) {
key := TraceCode("key")
val, ok := ctx.Value(key).(string)
wg.Done()
if !ok {
fmt.Println("get val failed")
}
fmt.Println(val)
}
//context.WithValue
func main() {
ctx, cancel := context.WithTimeout(context.Background(), time.Millisecond*50)
ctx = context.WithValue(ctx, TraceCode("key"), "ce shi cheng gong")
wg.Add(1)
go worker(ctx)
time.Sleep(time.Second * 5)
cancel()
wg.Wait()
}
客户端超时取消示例
server端
package main
import (
"fmt"
"math/rand"
"net/http"
"time"
)
// server端,随机出现慢响应
func indexHandler(w http.ResponseWriter, r *http.Request) {
num := rand.Intn(2) //创建一个随机数
if num == 0 {
time.Sleep(time.Second * 10)// 耗时10秒的慢响应
fmt.Fprintf(w, "slow response")
return
}
fmt.Fprint(w, "quick response")
}
func main() {
http.HandleFunc("/", indexHandler)
err := http.ListenAndServe("127.0.0.1:8000", nil)
if err != nil {
fmt.Printf("open server failed err:%v\n", err)
}
}
client
package main
import (
"context"
"fmt"
"io/ioutil"
"net/http"
"sync"
"time"
)
type respData struct {
resp *http.Response
err error
}
func doCall(ctx context.Context) {
transport := http.Transport{ // 开启短链接
// 请求频繁可定义全局的client对象并启用长链接
// 请求不频繁使用短链接
DisableKeepAlives: true,
}
client := http.Client{ //创建一个客户端
Transport: &transport,
}
respChan := make(chan *respData, 1)
req, err := http.NewRequest("GET", "http://127.0.0.1:8000/", nil) //创建一个请求体
if err != nil {
fmt.Println("get url falied err:%v\n", err)
}
req = req.WithContext(ctx) // 使用带超时的ctx创建一个新的client request
var wg sync.WaitGroup
wg.Add(1)
defer wg.Wait()
go func() {
resp, err := client.Do(req) //访问请求体
fmt.Printf("client.do resp:%v, err:%v\n", resp, err)
rd := &respData{
resp: resp,
err: err,
}
respChan <- rd
wg.Done()
}()
select {
case <-ctx.Done():
fmt.Println("call url timeout")
case result := <-respChan:
if result.err != nil {
fmt.Printf("call server api falied err%v\n", result.err)
}
defer result.resp.Body.Close()
repss, err := ioutil.ReadAll(result.resp.Body)
if err != nil {
fmt.Println("get body failed err:", err)
}
fmt.Println(string(repss))
}
}
func main() {
// 定义一个100毫秒的超时
ctx, cancel := context.WithTimeout(context.Background(), time.Millisecond*100)
defer cancel() // 调用cancel释放子goroutine资源
doCall(ctx)
}
日志收集项目
日志收集项目架构
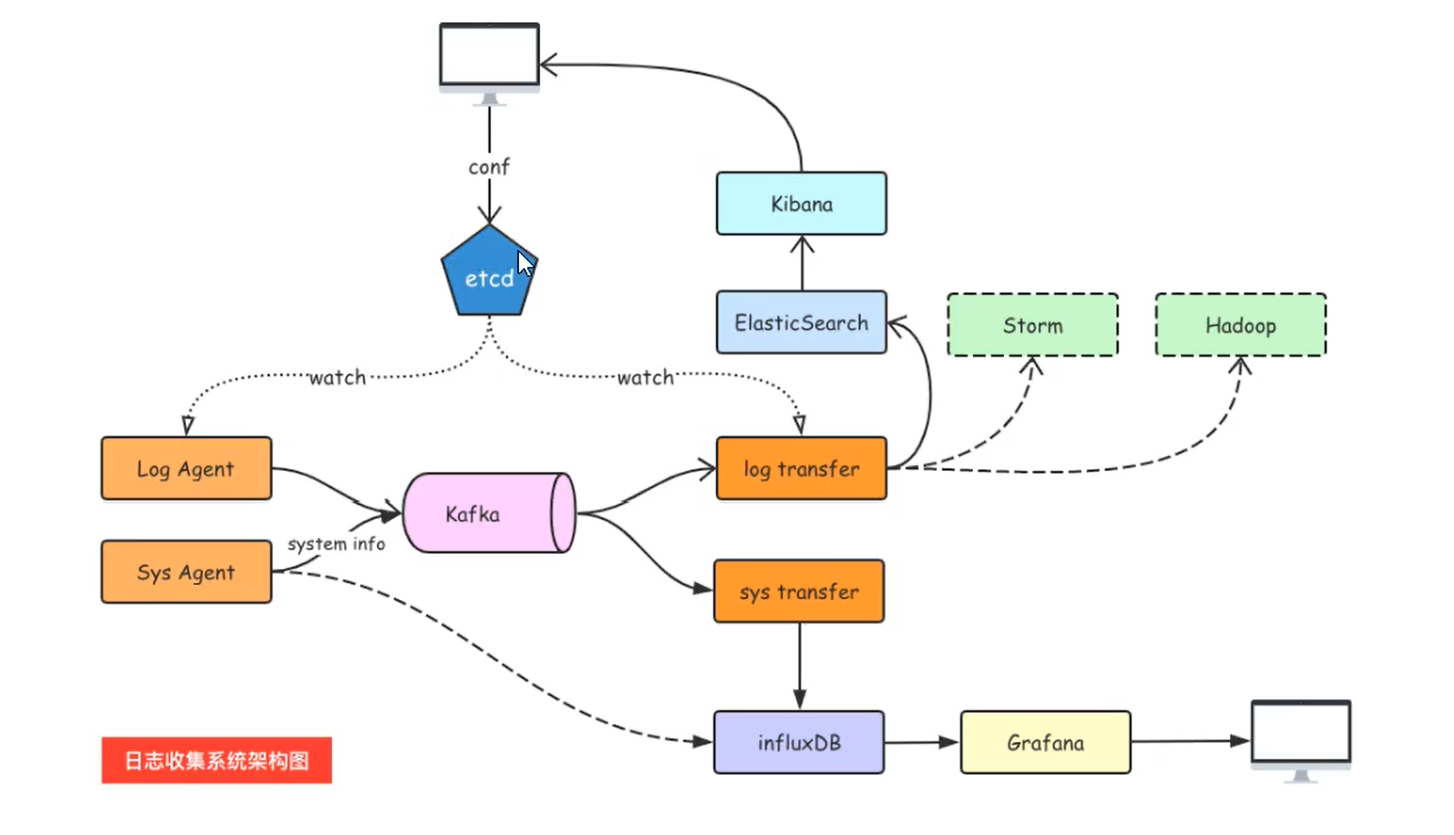
组件介绍
LogAgent:日志收集客户端,用来收集服务器上的日志。
Kafka:高吞吐量的分布式队列(Linkin开发,apache顶级开源项目)
ElasticSearch:开源的搜索引擎,提供基于HTTP RESTful的web接口
Kibaa:开源的ES数据分析和可视化工具。
Hadoop:分布式计算框架,能够对大量数据进行分布式处理的平台
Storm:一个免费并开源的分布式实时计算系统
学到的技能
- 服务端agent开发
- 后端服务组件开发
- Kafka和zookeeper的使用
- Es和Kibana的使用
- etcd的使用
消息队列的通信模型
点对点模式(queue)
消息生产者生产消息发送到queue中,然后消息消费者从queue中取出并消费消息。一条消息被消费以后,queue中就没有了,不存在重复消费
发布/订阅(topic)
消息生产者(发布)将消息发布到topic中,同时有多个消息消费者(订阅)消费该消息。和点对点方式不同,发布到topic的消息会被所有订阅者消费

Kafka
介绍
Kafka是一个分布式数据流平台,可以运行在单台服务器上,也可以在多台服务器上部署形成集群,它提供了发布和订阅功能,使用者可以发送数据到Kafka中,也可以从Kafka中读取数据(以便进行后续的处理)。Kafka具有高吞吐、低延迟、高容错等特点 kafka官网

架构介绍
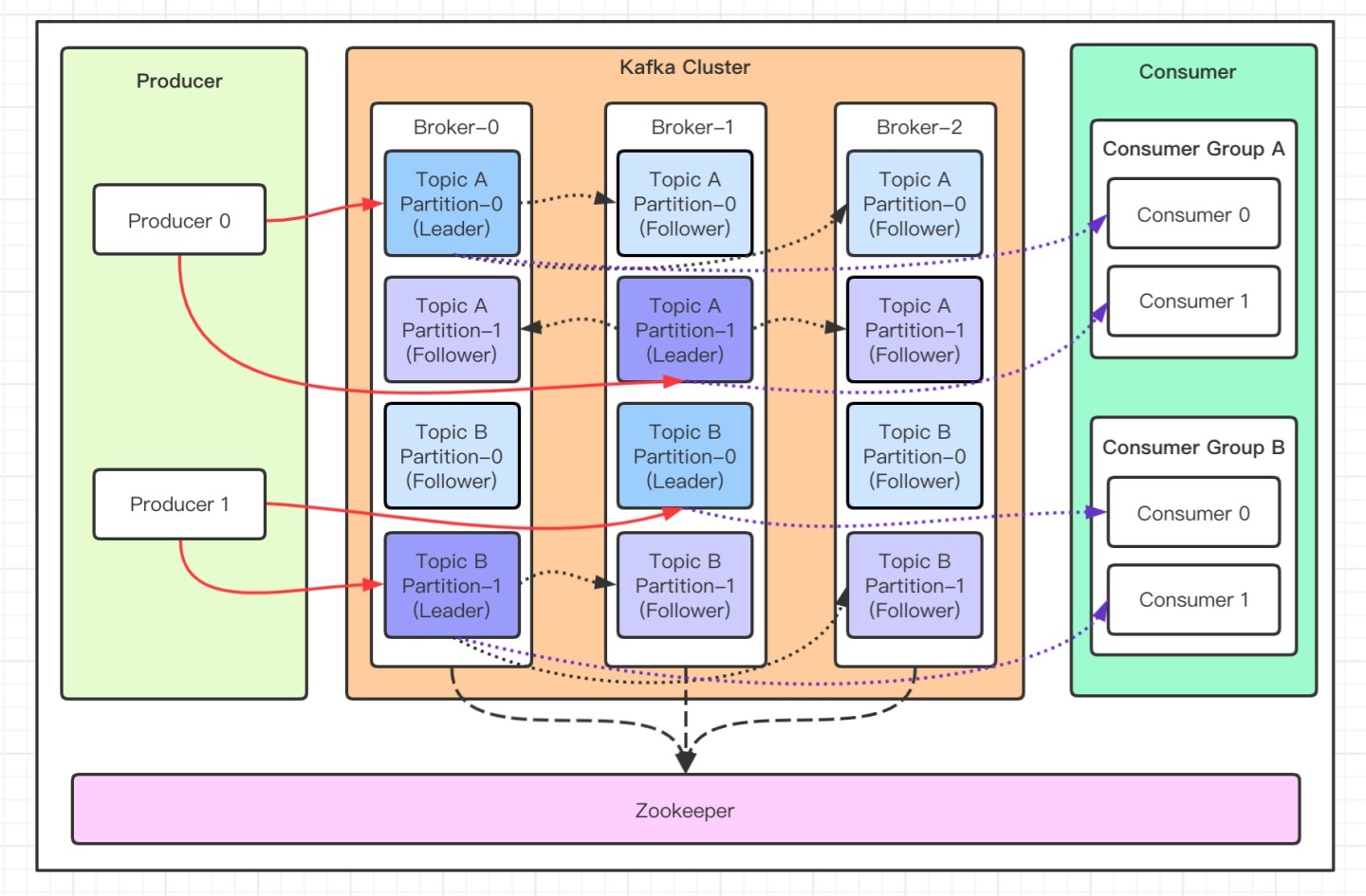
- Producer:Producer 即生产者,消息的产生者,是消息的入口
- Broker:Broker 是 kafka 一个实例,每个服务器上有一个或多个 kafka 的实例,简单的理解就是一台 kafka 服务器,
kafka cluster表示集群的意思 - Topic:消息的主题,可以理解为消息队列,kafka的数据就保存在topic。在每个 broker 上都可以创建多个 topic 。
- Partition:Topic的分区,每个 topic 可以有多个分区,分区的作用是做负载,提高 kafka 的吞吐量。同一个 topic 在不同的分区的数据是不重复的,partition 的表现形式就是一个一个的文件夹!
- Replication:每一个分区都有多个副本,副本的作用是做备胎,主分区(Leader)会将数据同步到从分区(Follower)。当主分区(Leader)故障的时候会选择一个备胎(Follower)上位,成为 Leader。在kafka中默认副本的最大数量是10个,且副本的数量不能大于Broker的数量,follower和leader绝对是在不同的机器,同一机器对同一个分区也只可能存放一个副本
- Message:每一条发送的消息主体。
- Consumer:消费者,即消息的消费方,是消息的出口。
- Consumer Group:我们可以将多个消费组组成一个消费者组,在 kafka 的设计中同一个分区的数据只能被消费者组中的某一个消费者消费。同一个消费者组的消费者可以消费同一个topic的不同分区的数据,这也是为了提高kafka的吞吐量!
- Zookeeper:kafka 集群依赖 zookeeper 来保存集群的的元信息,来保证系统的可用性
工作流程
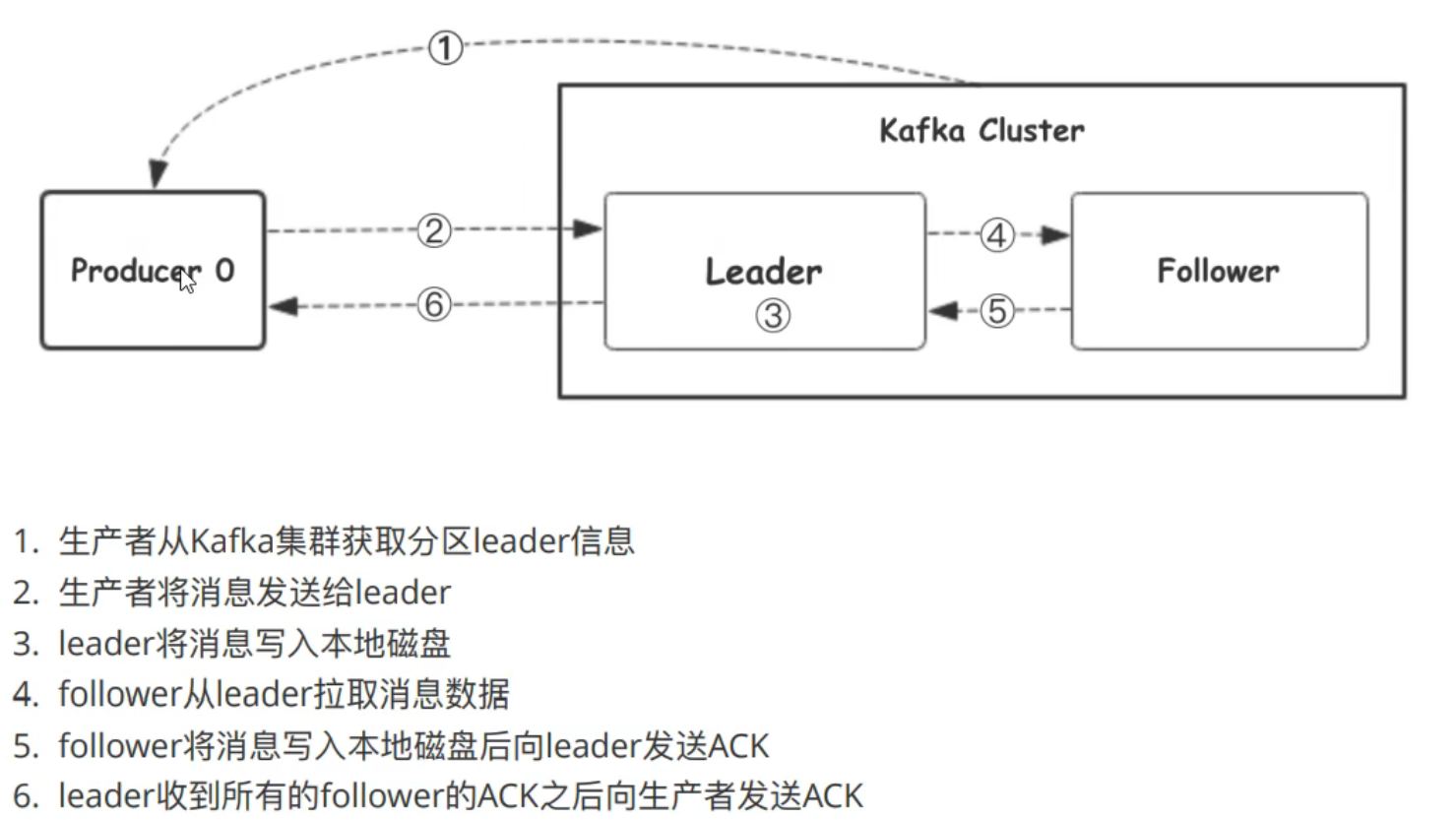
选择partition的原则

ACK应答机制

分区存储文件的原理
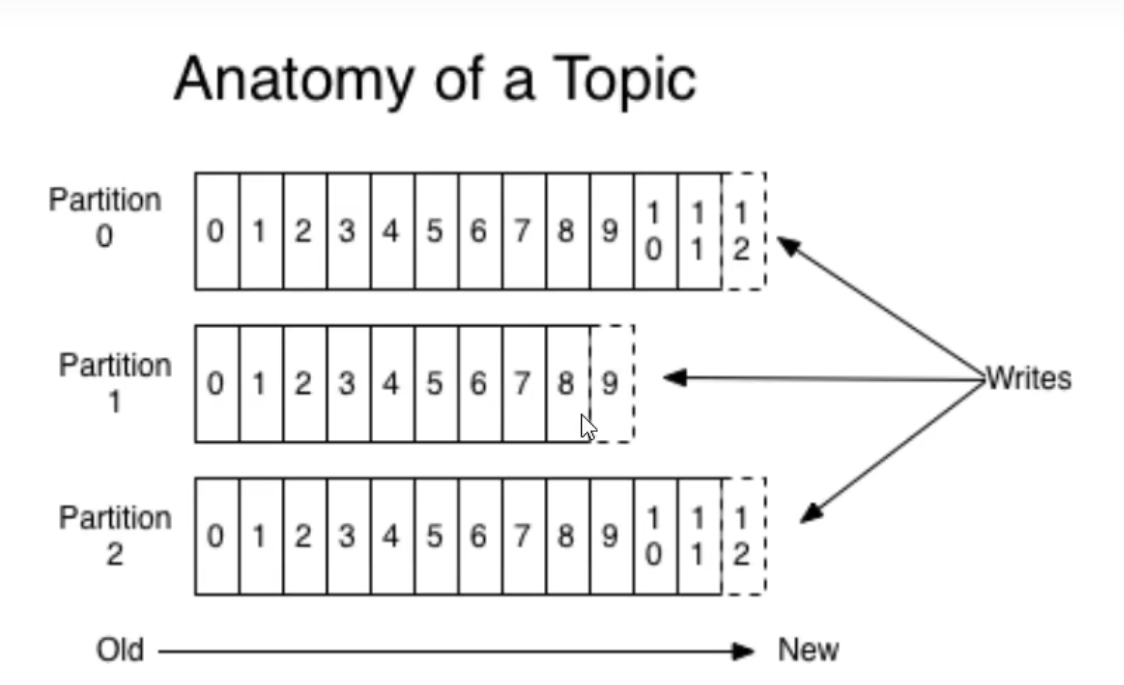
每个partition都是一个有序并且不可变的消息记录集合,当新的数据写入时,就被追加到partition的末尾,在每个partition中,每条消息都会被分配一个顺序的唯一标识,这个表示被称为offset,即偏移量。注意,Kafka只保证在同一个partition内部消息是有序的,在不同partition之间,并不能保证消息有序
为什么说Kafka读取速度快?
因为Kafka是顺序读,通过表示进行读取
消费组消费数据的原理
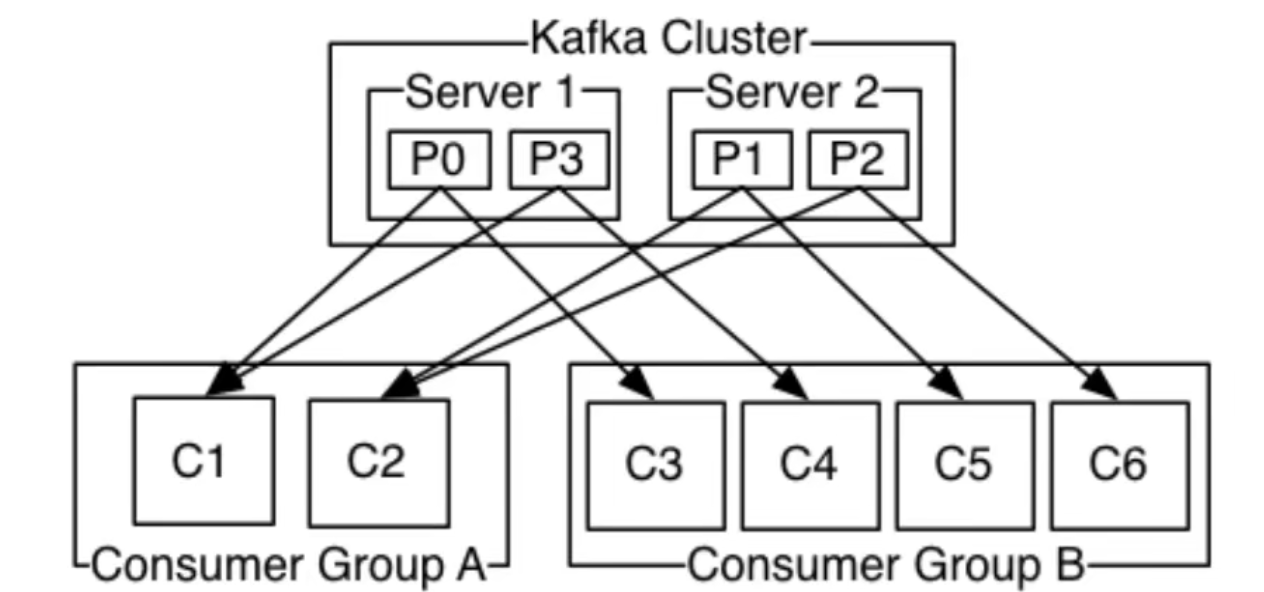
消费组中每个消费者不能消费同一个partition分区,每个消费者可以消费多个分区
下载以及启动
kafka下载
windows启动kafka
启动zookeeper
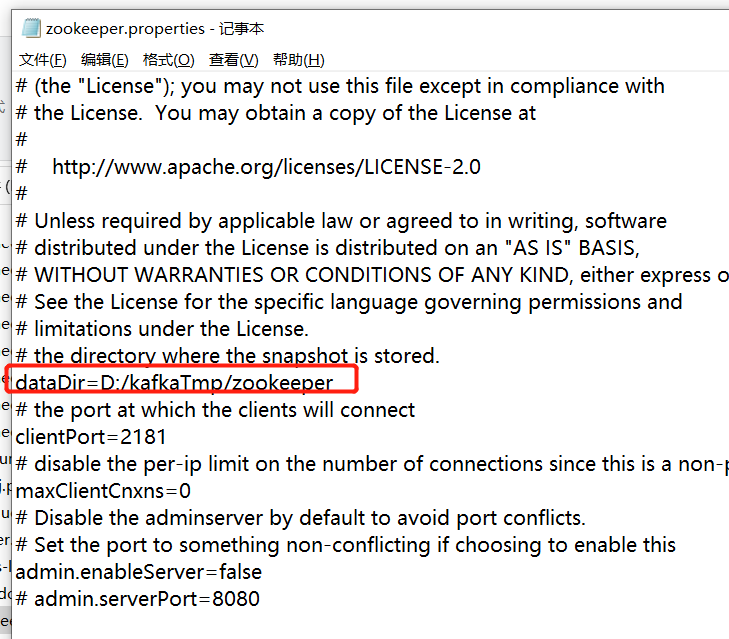
修改配置文件
启动
D:\Kafka>bin\windows\zookeeper-server-start.bat config\zookeeper.properties
#D:\Kafka kafka路径
#zookeeper.properties zookeeper配置文件
启动kafaka
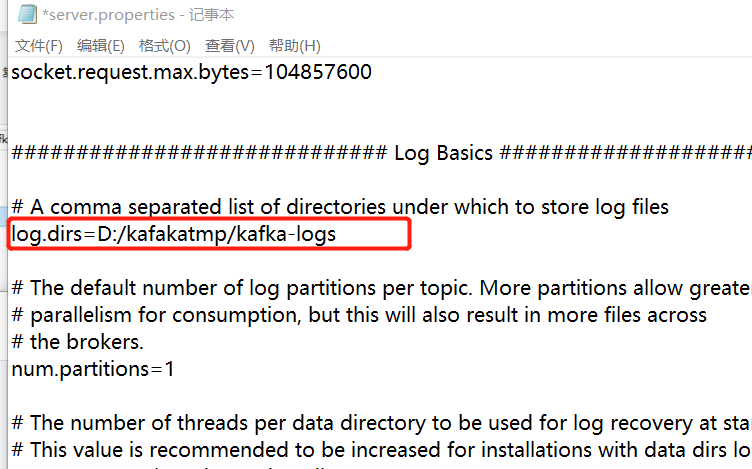
修改配置文件
启动
D:\Kafka> bin\windows\kafka-server-start.bat config\server.properties
#D:\Kafka kafka路径
#server.properties kafka配置文件
终端kafka消费者
bin\windows\kafka-console-consumer.bat --bootstrap-server=127.0.0.1:9092 --topic=web_test --from-beginning
LogAgent的工作流程
使用tail第三方库进行读日志将日志写往kafka
通过etcd实现一个热更新配置和多配置的实现
- logAgent的主要功能能够实现热更新配置,部署简单
1. 读日志 --tail第三方库github.com/hpcloud/tail
package main
import (
"fmt"
"time"
"github.com/hpcloud/tail"
)
func main() {
fileName := "./log.log"
config := tail.Config{
ReOpen: true,
Follow: true,
Location: &tail.SeekInfo{Offset: 0, Whence: 2},
MustExist: false,
Poll: true,
}
tails, err := tail.TailFile(fileName, config)
if err != nil {
fmt.Println("tail file failed ,err:", err)
return
}
var (
line *tail.Line
ok bool
)
for {
line, ok = <-tails.Lines
if !ok {
fmt.Printf("tail file close reopen,fileName:%s\n", fileName)
time.Sleep(time.Second * 1)
continue
}
fmt.Println("line", line.Text)
}
}
2. 往kafka写日志 --sarama第三方库
package main
import (
"fmt"
"github.com/Shopify/sarama"
)
func main() {
config := sarama.NewConfig()
config.Producer.RequiredAcks = sarama.NoResponse //发送完数据即返回acks
config.Producer.Partitioner = sarama.NewHashPartitioner //新选出一个分区
config.Producer.Return.Successes = true //成功交付时返回success channel 返回
//构建一个消息
msg := &sarama.ProducerMessage{
Topic: "web_test_log",
Value: sarama.StringEncoder("this is web test log"),
}
//连接kafka
cliend, err := sarama.NewSyncProducer([]string{"127.0.0.1:9092"}, config)
if err != nil {
fmt.Println("producer closed,err:", err)
}
artition, offset, err := cliend.SendMessage(msg)
fmt.Println("artition:", artition, "offset:", offset)
}
etcd
etcd是使用GO语言开发的一个开源的、高可用的分布式key-value存储系统,可以用于配置共享和服务的注册和发现
类似项目有zookeeper和consul。

Raft协议
aft 是一种更为简单方便易于理解的分布式算法,主要解决了分布式中的一致性问题。相比传统的 Paxos 算法,Raft 将大量的计算问题分解成为了一些简单的相对独立的子问题,并有着和 Multi-Paxos 同样的性能,下面我们通过动图,以后还原 Raft 内部原理。
Raft协议一共包含如下3类角色:
- Leader(领袖):领袖由群众投票选举得出,每次选举,只能选出一名领袖;
- Candidate(候选人):当没有领袖时,某些群众可以成为候选人,然后去竞争领袖的位置;
- Follower(群众):这个很好理解,就不解释了。
角色转换
这幅图是领袖、候选人和群众的角色切换图,我先简单总结一下:
- 群众 -> 候选人:当开始选举,或者“选举超时”时
- 候选人 -> 候选人:当“选举超时”,或者开始新的“任期”
- 候选人 -> 领袖:获取大多数投票时
- 候选人 -> 群众:其它节点成为领袖,或者开始新的“任期”
- 领袖 -> 群众:发现自己的任期ID比其它节点分任期ID小时,会自动放弃领袖位置
1.选举
领袖由群众投票选举得出,每次选举,只能选出一名领袖;
候选人选举:每个节点都有自己的“超时时间”,因为是随机的,区间值为150~300ms,所以出现相同随机时间的概率比较小,节点最先超时,它就成为候选人。
选举领导人:候选人B开始发起投票,群众A和C返回投票,当候选人B获取大部分选票后,选举成功,候选人B成为领袖。
选举过程
- 服务器启动时,所有节点最初都是follower,follower听不到leader的心跳消息时,选举时间超时(心跳肯定超时),说明当前没有leader(或者leader挂了)。
- 此时开始选举阶段:谁的选举计时先完成则此follower先成为candidate。Follower将其当前term加一,因为这是开启了一个新的任期。
- candidate争取选票,它首先给自己投票并且给集群中的其他服务器发送 RequestVote RPC。
- 此时可能出现以下三种情况:
- 如果争取到超过半数的选票,那么该candidate成为leader
- 收到了Leader的消息,表示有其它服务器已经抢先当选了Leader;
- 没有服务器赢得多数的选票:比如说两个candidate同时发起选举,Leader选举失败,等待选举时间超时后发起下一次选举。
- 当选举完成:新Leader会立刻给所有节点发消息,避免其他节点触发新的选举。当候选人被告知Leader已产生,则自行切换为Follower,后面leader会定期发送心跳给follower
2.日志复制机制
- Leader接收到指令后写入到本地日志,在随后的心跳中(AppendEntries)向其他follower发送该指令
- 每个follower收到指令会,存储日志,并向leader立即返回确认
- leader等待收到过半follower响应确认后,将该条目标志位已提交状态(也就是当日志复制到大多数机器上的时候,就认为该跳命令可以提交了),并发往leader状态机执行该指令,执行完成后返回结果给客户端;
- leader在后续心跳包(AppendEntries)中通知所有追随者该条目为已提交状态。follower就也会更新该条目为已提交状态并且在各自状态机中执行该指令。
3.异常处理
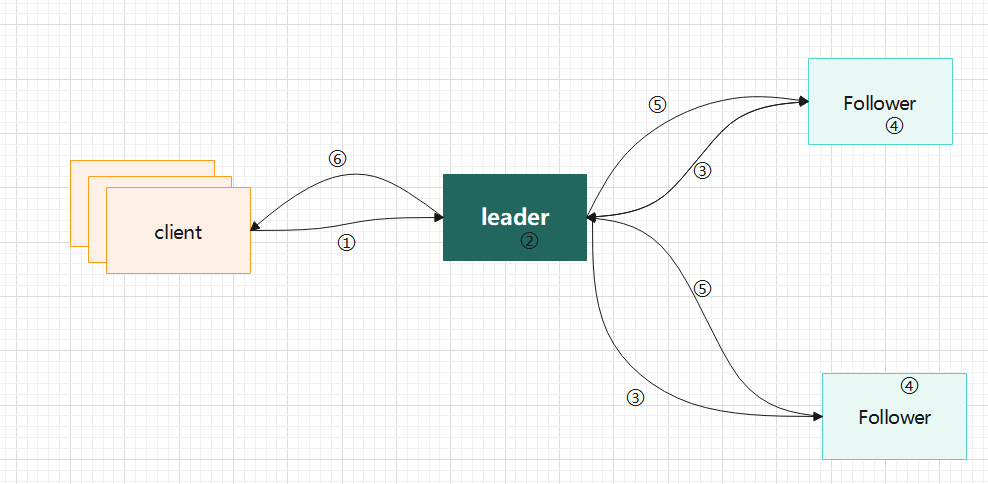
- 若在 client 发送日志请求给 leader 前,leader 就已经故障。此时 client 的请求被拒绝,导致客户端重试(需要重试其他节点),后续集群会选举出新的 leader 来处理 client 的请求;
- 若 leader 顺利接收 client 的日志提交请求,并将它持久化到本地,但还未复制给集群其他 follower 就故障了。此时 client 的请求会超时,类似的,其将重试(具体重试策略可包含先重试 leader 再重试其他节点),后续集群会选举出新 leader,该条日志请求仅在旧 leader 上存在,且其以 follower 角色重启加入集群后,其日志将被新 leader 覆盖;
- 若 leader 顺利接收 client 的日志提交请求,但只成功将其复制到少数节点,然后 leader 宕机了。此时,对于 client 而言,其处理策略同 2 类似,因为该日志仅存在少数节点,因此新选举出的 leader 可能包含该日志,也可能不包含该日志,但这都不影响协议正确性。若新 leader 不包含该日志,则 client 后续会再次提交该日志请求,最终该请求被提交和应用到状态机。若新 leader 包含该日志,则若 client 后续再次提交该日志请求,可能导致 leader 重复添加日志到状态机,但状态机必须具备检测重复日志提交请求的能力,且客户端应该给每个日志请求赋予一个递增的唯一标识,即除非 leader 返回错误给 client,client 才会使用同一请求序号重试,当然,这都取决于状态机的实现;
- 若 leader 顺利地将从 client 接收的日志请求复制到 majority 节点,但还未提交就宕机了。此时,新选举出的 leader 必然包含该日志,因此该日志最终会被提交,而 client 的行为则同 3 类似,且状态机同样需要保证同一日志请求只应用一次;
- 若 leader 顺利收到所有 follower 响应,因此 leader 提交了该日志请求,但随后就宕机了。此时 client 的行为和集群后续处理机制同 4;
- 若某个 follower 接收了 leader 的日志复制请求并将其持久化到本地,并成功响应,然后就挂了,且很不幸的是,因为某种原因最新保存的日志丢失了。此时,该 follower 需要以一个新成员的身份加入集群,而不能以之前的身份标识加入集群。因为若以之前的身份标识加入集群,则很可能导致一个新选举出的 leader 将另一条日志同步给它以及其他少数的 follower 节点,并最终覆盖了旧 leader 已提交的日志,这违反了协议正确性;(比如有节点 S1、S2 和 S3,旧 leader S1 宕机了,且其只将该日志复制到了 majoirty 节点(S1 和 S2),但因为 S2 日志丢失,因此 S2 重启后可为新 leader S3 投票,导致 S3 将新日志覆盖到旧 leader S1 已提交的日志索引位置)
4.zookeeper的zad协议的区别
相同点
采用 quorum 来确定整个系统的一致性,这个 quorum 一般实现是集群中半数以上的服务器,
zookeeper 里还提供了带权重的 quorum 实现.
都由 leader 来发起写操作.
都采用心跳检测存活性
leader election 都采用先到先得的投票方式不同点
- zab 用的是 epoch 和 count 的组合来唯一表示一个值, 而 raft 用的是 term 和 index
- zab 的 follower 在投票给一个 leader 之前必须和 leader 的日志达成一致,而 raft 的 follower则简单地说是谁的 term 高就投票给谁
- raft 协议的心跳是从 leader 到 follower, 而 zab 协议则相反
- raft 协议数据只有单向地从 leader 到 follower(成为 leader 的条件之一就是拥有最新的 log), 而 zab 协议在 discovery 阶段, 一个 prospective leader 需要将自己的 log 更新为 quorum 里面最新的 log,然后才好在 synchronization 阶段将 quorum 里的其他机器的 log 都同步到一致
etcd应用场景

配置中心

分布式锁


etcd架构
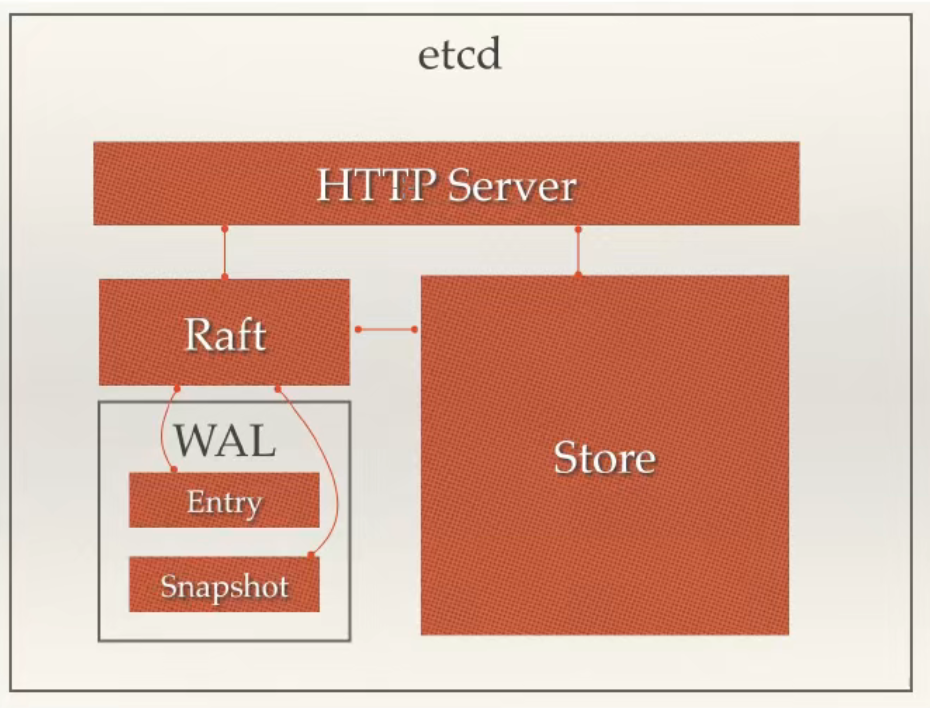
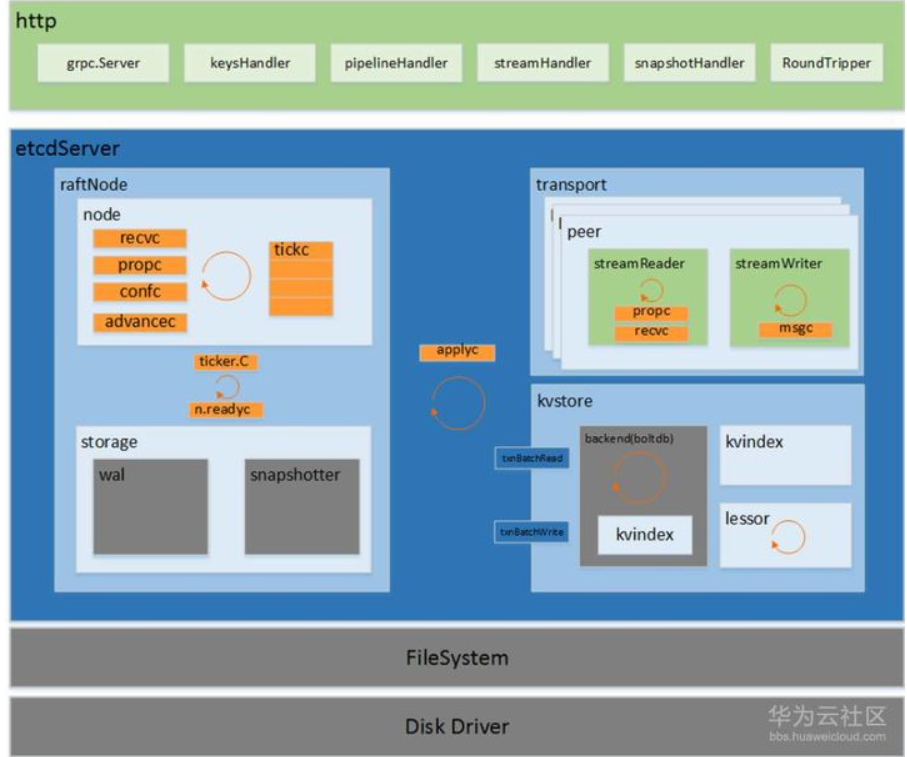
HTTP Server:接受客户端发出的 API 请求以及其它 etcd 节点的同步与心跳信息请求。
Store:用于处理 etcd 支持的各类功能的事务,包括数据索引、节点状态变更、监控与反馈、事件理与执行等等,是etcd 对用户提供的大多数 API 功能的具体实现。
Raft:强一致性算法的具体实现,是 etcd 的核心算法。
WAL(Write Ahead Log,预写式日志):是 etcd 的数据存储方式,etcd 会在内存中储存所有数据状态以及节点的索引,此外,etcd 还会通过 WAL 进行持久化存储。WAL 中,所有的数据提交前会事先记录日志。
- Snapshot 是为了防止数据过多而进行的状态快照;
- Entry 表示存储的具体日志内容。
通常,一个用户的请求发送过来,会经由 HTTP Server 转发给 Store 进行具体的事务处理,如果涉及到节点数据的修改,则交给 Raft 模块进行状态的变更、日志的记录,然后再同步给别的 etcd 节点以确认数据提交,最后进行数据的提交,再次同步。
配置部署
go操作etcd
etcd官方文档
https://github.com/etcd-io/etcd/tree/main/client/v3
下载包
go get go.etcd.io/etcd/client/v3
连接etcd
//连接etcd
cli, err := clientv3.New(clientv3.Config{
Endpoints: []string{"127.0.0.1:2379"},
DialTimeout: 5 * time.Second,
})
if err != nil {
fmt.Println("new etcd falied err:", err)
}
fmt.Println("etcd连接成功")
defer cli.Close()
put(上传数据)
//put
ctx, cancel := context.WithTimeout(context.Background(), time.Second)
resp, err := cli.Put(ctx, "shangke", "woknm")
cancel()
if err != nil {
fmt.Println("put value falied err:", err)
}
fmt.Println(resp)
get(获取数据)
//get
ctx, cancel = context.WithTimeout(context.Background(), time.Second)
resps, err := cli.Get(ctx, "shangke")
cancel()
if err != nil {
fmt.Println("get value falied err:", err)
}
for _, ev := range resps.Kvs {
fmt.Printf("%v:%v\n", string(ev.Key), string(ev.Value))
}
watch(检测更新数据)
//watch
watCh := cli.Watch(context.Background(), "shangke")
for evp := range watCh {
for _, evt := range evp.Events {
fmt.Println(evt.Type, string(evt.Kv.Key), ":", string(evt.Kv.Value))
}
}
综合代码
综合代码见本地路径
D:\GoPackage\src\com.haojuetrace\01Package\work\logAgent
Logtransfer
从kafka里面吧日志取出来,写入ES,使用Kibana做可视化的展示
Elastic search
下载官方
https://www.elastic.co/cn/downloads/elasticsearch
elastic search 和kibana的版本要一直
介绍
Elasticsearch(ES)是一个基于Lucene构建的开源、分布式、RESTful接口的全文搜索引擎。Elasticsearch还是一个分布式文档数据库,其中每个字段均可被索引,而且每个字段的数据均可被搜索,ES能够横向扩展至数以百计的服务器存储以及处理PB级的数据。可以在极短的时间内存储、搜索和分析大量的数据。通常作为具有复杂搜索场景情况下的核心发动机。
Elasticsearch能做什么
- 当你经营一家网上商店,你可以让你的客户搜索你卖的商品。在这种情况下,你可以使用ElasticSearch来存储你的整个产品目录和库存信息,为客户提供精准搜索,可以为客户推荐相关商品。
- 当你想收集日志或者交易数据的时候,需要分析和挖掘这些数据,寻找趋势,进行统计,总结,或发现异常。在这种情况下,你可以使用Logstash或者其他工具来进行收集数据,当这引起数据存储到ElasticsSearch中。你可以搜索和汇总这些数据,找到任何你感兴趣的信息。
- 对于程序员来说,比较有名的案例是GitHub,GitHub的搜索是基于ElasticSearch构建的,在github.com/search页面,你可以搜索项目、用户、issue、pull request,还有代码。共有40~50个索引库,分别用于索引网站需要跟踪的各种数据。虽然只索引项目的主分支(master),但这个数据量依然巨大,包括20亿个索引文档,30TB的索引文件。
安装
进入官方网页
进行下载
将文件发送到linux中
此过程省略
解压压缩包
[root@localhost elasticsearch]# tar zxf kelasticsearch-8.3.1-linux-x86_64.tar.gz
查看
[es@localhost elasticsearch]$ ls
elasticsearch-8.3.1
修改配置
network.host: 0.0.0.0 #不设置这个只能服务器本机使用
http.port: 9200 #服务端口
xpack.security.enabled: false #关闭身份验证
xpack.security.http.ssl:
enabled: false #关闭ssl
keystore.path: certs/http.p12
创建用户
用户随便都行 这一步是为了启动Kibana 因为Kibana不能用root用户启动
[root@localhost elasticsearch-8.3.1]# useradd es
[root@localhost elasticsearch-8.3.1]# passwd es
Changing password for user es.
New password:
BAD PASSWORD: The password is shorter than 8 characters
Retype new password:
passwd: all authentication tokens updated successfully.
授权文件夹
[root@localhost ~]# chown -R es:es elasticsearch/
[root@localhost ~]# chmod 777 elasticsearch/
启动服务
[es@localhost elasticsearch-8.3.1]$ bin/elasticsearch
go操作elasticsearch
连接
client, err := elastic.NewClient(elastic.SetURL("http://192.168.54.100:9200"))
if err != nil {
// Handle error
panic(err)
}
fmt.Println("connect to es success")
发送数据
type student struct {
Name string `json:"name"`
Age int `json:"age"`
}
#client为连接成功后的客户端
p1 := student{Name: "rion2", Age: 22}
put1, err := client.Index().
Index("student1").
BodyJson(p1).
Do(context.Background())
if err != nil {
// Handle error
panic(err)
}
fmt.Printf("Indexed user %s to index %s, type %s\n",put1.Id,put1.Index, put1.Type)
Kibana
下载官网
https://www.elastic.co/cn/downloads/kibana
介绍
Kibana 是一种数据可视化和挖掘工具,可以用于日志和时间序列分析、应用程序监控和运营智能使用案例。它提供了强大且易用的功能,例如直方图、线形图、饼图、热图和内置的地理空间支持。此外,它还提供了与 Elasticsearch 的紧密集成,后者是一款流行的分析和搜索引擎,这使得 Kibana 成为了可视化 Elasticsearch 中存储数据的默认之选
安装
进入官方下载页面
将文件发送到linux下

解压压缩包
[root@localhost kibana]# tar zxf kibana-8.3.1-linux-x86_64.tar.gz
查看
[root@localhost kibana]# ls
kibana-8.3.1 kibana-8.3.1-linux-x86_64.tar.gz
修改配置
#/etc/kibana/kibana-8.3.1/config/kibana.yml为Kibana配置路径根据自己的改
vim /etc/kibana/kibana-8.3.1/config/kibana.yml
server.host: "192.168.54.100" #这里的ip是我本地的ip
elasticsearch.hosts: ["http://192.168.54.100:9200"] #这里的地址是elasticsearch的api地址
i18n.locale: "zh-CN" #设置成中文
#如下需要可以设置 不设置可以会出现警告
xpack.reporting.roles.enabled: false
xpack.encryptedSavedObjects.encryptionKey: encryptedSavedObjects12345678909876543210
xpack.security.encryptionKey: encryptionKeysecurity12345678909876543210
xpack.reporting.encryptionKey: encryptionKeyreporting12345678909876543210
xpack.screenshotting.browser.chromium.disableSandbox: true
给文件夹授权
[root@localhost ~]# chown -R es:es kibana/
[root@localhost ~]# chmod 777 kibana/
启动
#切记不能用root用户启动Kibana
[root@localhost ~]# su es
[es@localhost kibana-8.3.1]$ bin/kibana
系统监控
gopsutil工具包做系统监控信息的采集,写入influxDB,使用grafana作展示
- 一个自己开发系统监控的工具包
prometheus监控:采集性能指标数据,保存起来,使用grafana作展示
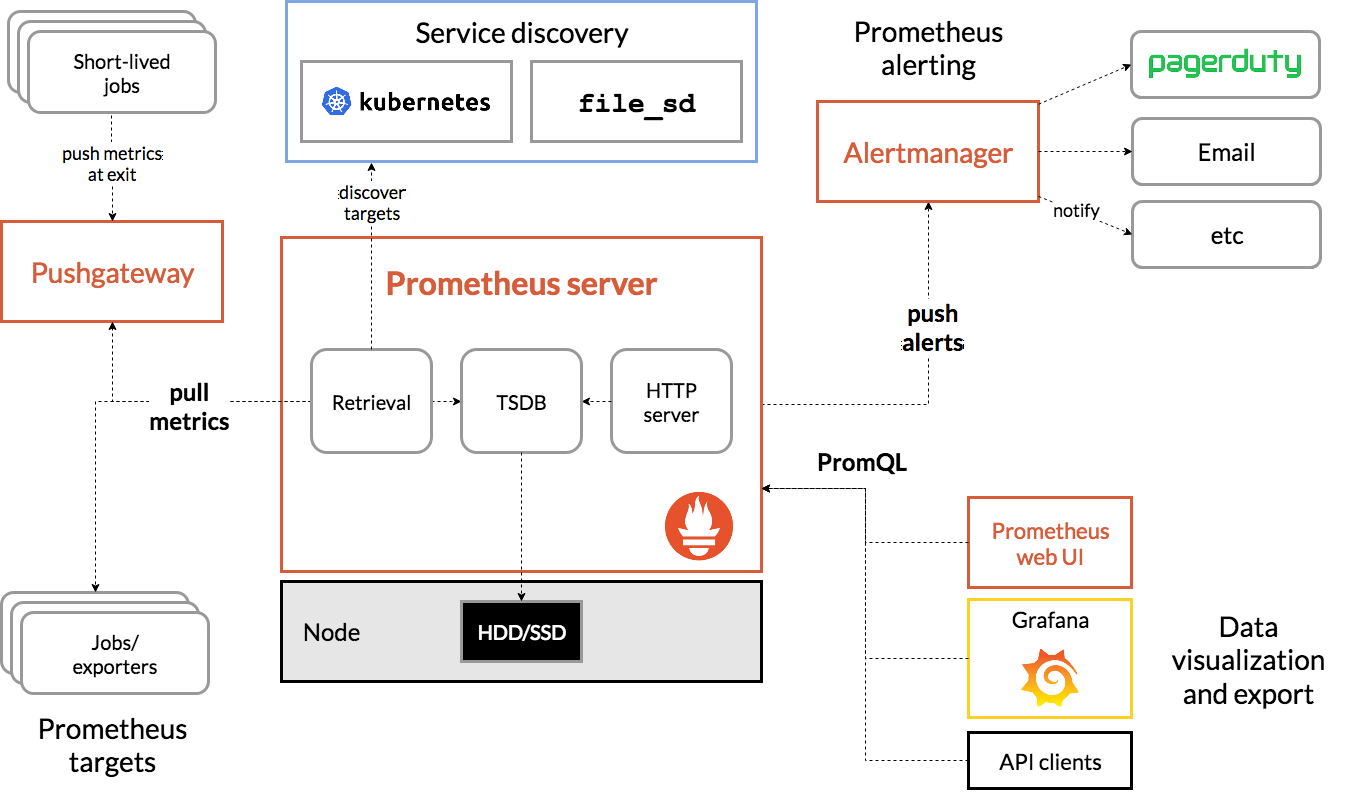
prometheus
官网:https://prometheus.io/
架构图:
grafana
官网:https://grafana.com/
图像化界面
项目总结
- 项目的架构
- 为什么不用ELK
- logAgent里面如何保证日志不丢/重启之后继续收集日志(记录读取文件的offset)
- kafka的相关知识点
- etcd的watch的原理
- es相关知识点
http/template标准库
html/template包实现了数据驱动的模板,用于生成可防止代码注入的安全的HTML内容。它提供了和text/template包相同的接口,Go语言中输出HTML的场景都应使用html/template这个包。
模板与渲染
在一些前后端不分离的Web架构中,我们通常需要在后端将一些数据渲染到HTML文档中,从而实现动态的网页(网页的布局和样式大致一样,但展示的内容并不一样)效果。
我们这里说的模板可以理解为事先定义好的HTML文档文件,模板渲染的作用机制可以简单理解为文本替换操作–使用相应的数据去替换HTML文档中事先准备好的标记。
很多编程语言的Web框架中都使用各种模板引擎,比如Python语言中Flask框架中使用的jinja2模板引擎。
Go语言的魔板引擎
Go语言内置了文本模板引擎
text/template和用于HTML文档的html/template。它们的作用机制可以简单归纳如下:
- 模板文件通常定义为
.tmpl和.tpl为后缀(也可以使用其他的后缀),必须使用UTF8编码。- 模板文件中使用
{{和}}包裹和标识需要传入的数据。- 传给模板这样的数据就可以通过点号(
.)来访问,如果数据是复杂类型的数据,可以通过{ { .FieldName }}来访问它的字段。- 除
{{和}}包裹的内容外,其他内容均不做修改原样输出。
解析模板
t, err := template.ParseFiles("./hello.tmpl")
if err != nil {
fmt.Println("parse template failed err:", err)
}
渲染模板
t.Execute(w, "haojuetrace")
模板语法
总实例
`main.go内容``
package main
import (
"fmt"
"net/http"
"text/template"
)
type user struct {
Name string
Sex string
Age int
}
func hello(w http.ResponseWriter, r *http.Request) {
//定义模板
//解析模板
t, err := template.ParseFiles("./hello.tmpl")
if err != nil {
fmt.Println("parse template failed err:", err)
}
u1 := user{
Name: "haojuetrace",
Sex: "男",
Age: 19,
}
u2 := map[string]interface{}{
"name": "张三",
"sex": "女",
"age": 18,
}
hobby := []string{
"唱",
"跳",
"rap",
"篮球",
}
//渲染模板
t.Execute(w, map[string]interface{}{
"u1": u1,
"u2": u2,
"h1": hobby,
})
}
func main() {
http.HandleFunc("/", hello)
err := http.ListenAndServe(":8989", nil)
if err != nil {
fmt.Println("listen add server failed err:", err)
}
}
`hello.tmpl内容``
<!DOCTYPE html>
<html>
<herd>
<title>hello</title>
</herd>
<body>
<h1>u1</h1>
{{ with .u1 }} {{/*with*/}}
<h1>hello {{ .Name }}</h1>
<h1>hello {{ .Age }}</h1>
<h1>hello {{ .Sex }}</h1>
{{ end }}
<br>
<h1>hello {{ .u2.name }}</h1>
<h1>hello {{ .u2.age }}</h1>
<h1>hello {{- .u2.sex -}}</h1>{{/*移除空格*/}}
<br>
{{$num1 := 100}} {{/*定义变量*/}}
{{$num2 := .u2.age}}
{{ if lt $num2 $num1}} {{/*条件判断*/}}
你真大
{{else}}
你真小
{{end}}
{{range $index,$hobby := .h1}} {{/*range遍历*/}}
<h1>{{ $index }}--{{ $hobby }}</h1>
{{else}}
没啥爱好
{{end}}
</body>
</html>
{{ . }}
{{ .Name }}
{{ . }}
注释
{{/*注释内容*/}}
变量
{{$num1 := 100}}
移除空格
{{- .u2.sex -}}
条件判断
{{ if lt $num2 $num1}} {{/*条件判断*/}}
你真大
{{else}}
你真小
{{end}}
range
{{range $index,$hobby := .h1}} {{/*range遍历*/}}
<h1>{{ $index }}--{{ $hobby }}</h1>
{{else}}
没啥爱好
{{end}}
with
{{ with .u1 }}
<h1>hello {{ .Name }}</h1>
<h1>hello {{ .Age }}</h1>
<h1>hello {{ .Sex }}</h1>
{{ end }}
比较函数
下面是定义为函数的二元比较运算的集合:
eq 如果arg1 == arg2则返回真
ne 如果arg1 != arg2则返回真
lt 如果arg1 < arg2则返回真
le 如果arg1 <= arg2则返回真
gt 如果arg1 > arg2则返回真
ge 如果arg1 >= arg2则返回真
使用方法
{{ lt $num2 $num1}}
自定义函数
jiao := func(name string) (any string, err error) {
return name + ",在吹牛逼", nil
}
t := template.New("f.tmpl")
t.Funcs(template.FuncMap{ //自定义函数一定要在解析模板之前定义
"jiao": jiao,
})
嵌套template
main.go
//定义模板
//解析模板
//定义个吹牛逼的函数
jiao := func(name string) (any string, err error) {
return name + ",在吹牛逼", nil
}
t := template.New("f.tmpl")
t.Funcs(template.FuncMap{
"jiao": jiao,
})
_, err := t.ParseFiles("./f.tmpl", "./u1.tmpl")
if err != nil {
fmt.Printf("parse template failed err:%v\n", err)
return
}
//渲染模板
t.Execute(w, "haojuetrace")
f.tmp
<!DOCTYPE html>
<html>
<herd>
<title>hello</title>
</herd>
<body>
{{$name := .}}
<H1>{{ jiao $name}}</H1>
{{template "u1.tmpl"}}
{{template "u2.tmpl"}}
{{define "u2.tmpl"}}
<ol>
<li>唱 {{.}}</li>
<li>跳 {{.}}</li>
<li>rap {{.}}</li>
<li>篮球 {{.}}</li>
</ol>
{{end}}
</body>
</html>
u1.tmpl
<!DOCTYPE html>
<html>
<herd>
<title>hello</title>
</herd>
<body>
<H1>张三 {{.}}</H1>
<H1>李四 {{.}}</H1>
<H1>王五 {{.}}</H1>
</body>
</html>
模板继承block
main.go
//定义模板(模板继承版本)
//解析模板
t, err := template.ParseFiles("./template/base.tmpl", "./template/index2.tmpl")
if err != nil {
fmt.Println("parse template failed err :", err)
}
//渲染模板
t.ExecuteTemplate(w, "index2.tmpl", "haojuetrace")
base.tmpl定义跟模板
<!DOCTYPE html>
<html lang="zh-CN">
<herd>
<title>模板继承</title>
<style>
*{
margin: 0;
}
.nav{
width: 100%;
height: 60px;
position: fixed;
top: 0;
background-color: coral;
}
.menu{
width: 60px;
height: 100%;
background-color: aqua;
position: fixed;
margin-top: 60px;
left: 0;
}
.content{
margin-top: 100px;
margin-left: 300px;
display: inline-block;
}
</style>
</herd>
<body>
<dev class="nav"></dev>
<dev class="menu"></dev>
<dev class="content">
{{block "content" .}}{{end}}
</dev>
</body>
</html>
index2.tmpl继承跟模板
{{template "base.tmpl" .}}
{{define "content"}}
<h1>这是index页面</h1>
<p>hello {{ . }}</p>
{{end}}
修改默认的标识符
//修改幕刃标识符一定要在解析模板之前
t, err := template.New("index.tmpl").
Delims("{[", "]}").
ParseFiles("./index.tmpl")
index.tmpl
<h1>hello {[ . ]}</h1>


文章评论